
@adlrocha - Beyond Bitswap (I)
Exchanging blocks the IPFS way!

Disclaimer: All the images of this publication were extracted from this awesome slide deck by Dirk at Protocol Labs.
When we think about exchaning content in a p2p network like IPFS, the first thing that comes to mind is the distributed hash-table (DHT). In IPFS content is addressed by hashing the content itself to create a content-identifier (CID). Intuition tells us that if we want to retrieve a block with the CID `QmPAwR…`, what our peer has to do is to go to his DHT, and trigger a lookup operation to find the specific peer storing the piece of information we want.In IPFS, this is correct as long as Bitswap has already failed in it's duty of finding blocks (more about this in a moment).
What we all initially learn about IPFS is that it uses three types of key-value pairings mapped using the DHT:
Provider Records that map a data identifier (i.e. multihash CID) to a peer that has advertised that they have, and are willing to provide the content (this is the DHT we mentioned above, and the one we are going to show interest in throughout this publication).
Peer Records that map a peerID to a set of multiaddresses at which the peer may be reached. It is our way of discovering nodes in the network and starting connections with them.
IPNS Records which map a IPNS key (hash of a public key) to a IPNS record.
From this we would expect that to find any content in the network we just have to make a lookup on the provider records DHT to find the peer that can serve us with this content. However, before doing that IPFS nodes implement an exchange interface to try and speed-up this process before having to resort to the to the DHT. If you want to dig deeper on DHTs and how IPFS leverages them, I highly recommend Adin's deep-dive into the DHT over on the IPFS blog.
However, the truth is that before doing that IPFS nodes implement an exchange interface to try and speed-up this process before having to resort to the to the DHT (by the way, if you want to dig deeper on DHTs and how IPFS leverages them, I highly recommend this post from the IPFS blog).
Content storage in IPFS
Before delving into how content is requested, we are going to make a quick detour to understand how information is stored in an IPFS network. IPFS uses a Merkle DAG structure to represent data. When you request the storage of a file to the network, your node splits the file in blocks. Blocks are linked to each other, and each of them is identified with a unique CID (the hash of the content). Splitting files into blocks means that each block is stored in a different node, so when you request the file different parts come from different sources and can be authenticated quickly.
The use of Merkle DAGs to store content also tackles the issue of redundancy of content in the network. If you are storing two similar files in the network, they will share parts of the Merkle DAGs, i.e. they share blocks that won’t necessarily need to be stored twice. But this separation of data in blocks also means that when we want to access specific content consisting of several blocks, we need to find all the nodes that store these blocks, and request their transmission. This is the reason for the existence of Bitswap in IPFS.

Say hello to Bitswap
Bitswap is the data trading module of IPFS. It manages requesting and sending blocks to and from peers. Bitswap has two main jobs:
Acquire blocks requested by our client from the network.
Send other nodes blocks that they have requested
So how exactly does Bitswap work? Imagine that we are searching for a file consisting of these three blocks: {CID1, CID2, CID3}, and whose root block (i.e. the root of the DAG that will allow us find the rest of the blocks of the file) is CID1. To get this file we would trigger a “get CID1'' operation in our node. This is the moment Bitswap comes into play. Bitswap starts its operation by sending a WANT message to all its connected peers requesting the block for CID1. If there is no response to this request, Bitswap’s work is done. Our node will go to the DHT to find the node that stores the CID and end of story (no speed-ups to the standard DHT content discovery achieved).

But what happens if some of our connected nodes answer to this request saying that they have this block and they send it to us? We will then remember these nodes and add them to the same session for that CID1. The fact that these nodes had the block for CID1 means that they may potentially have the rest of the blocks left for the file (CID2 and CID3). The reason why we want to remember nodes from a session is so that in the next round instead of blindly asking all our connected peers for the next CID of the DAG, flooding the network with our requests, we can narrow down a bit the search.
Now imagine that instead of getting a specific file where you don’t know the CIDs of the rest of the blocks, you want to recover a section of a Merkle DAG for which you know in advance the CIDs. In this case instead of sending a single WANT from your node, Bitswap will send a Wantlist, i.e. a list of WANTs of CIDs. Each node will remember the received Wantlists from other peers until they are cancelled so that if before the requesting node gets the block it is seen by the peer with the Wantlist, it can forward it to the requestor. Thus, receivers of a Wantlist will forward back any of the requested blocks as soon as they have it.
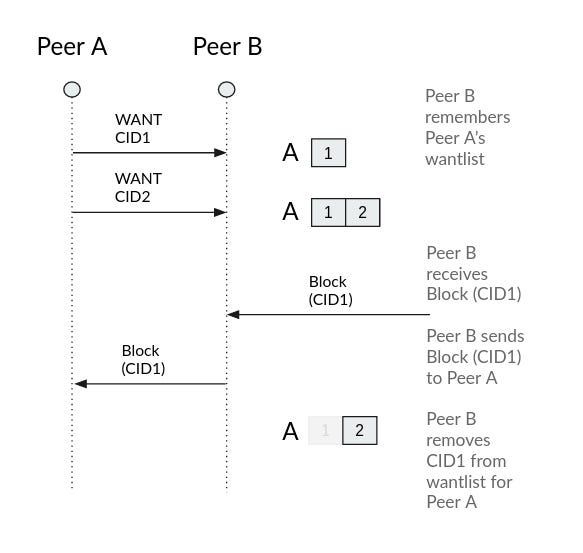
Finally, the reception of a block from a Wantlist in the requesting node triggers a CANCEL message to the rest of the nodes the Wantlist was sent to in order to signal them that the block was already received and it is not needed anymore.

Extensions to Bitswap
For me, some of Bitswap’s most pressing limitations are its inefficient use of bandwidth, and the fact that the discovery of blocks is performed blindly (in the sense that Bitswap only talks to its directly connected peers). Fortunately to work around these problems, some extensions to Bitswap have already been proposed and implemented:
The use of additional WANT-HAVE, WANT-BLOCK, and HAVE messages. Flatly requesting blocks from every peer could lead to duplicating the exchange of blocks from many of our connected peers. Instead, we can use these new Bitswap messages to express our desire for a block before actually requesting its transmission. This may increase the number of RTTs required to get a block, but reduces the bandwidth requirements of the protocol.
Intelligent peer selection algorithm in sessions. When a node tells us that it has the block we were requesting we add them to a session. Subsequent requests for a specific CID are exchanged with all the nodes in the corresponding session, but this exchange is blindly broadcasted to all of them. To make the protocol more efficient, some proposals have been made to intelligently select the peers in a session to which requests will be broadcasted in order to reduce the number of messages exchanged in the network. Thus, these requests will only be sent to nodes with the “highest score” in the session (i.e. nodes with the highest probability of having the block we are requesting).
In Bitswap we can only request a block (or group of blocks in a Wantlist) through their CID. We cannot request a full branch or a full subgraph of a DAG. To solve this, another content exchange protocol similar to Bitswap has been implemented in the IPFS ecosystem, Graphsync. Graphsync leverages the data model of IPLD (standard representation of Merkle DAG structures), and IPLD selectors (a way of performing queries over these structures). Instead of sending flat WANT requests to peers, an IPLD selector is included in the request.. What this selector is specifying is a query over a DAG structure, so instead of asking for specific blocks it is like asking others “hey guys, if someone has any of the blocks fulfilling this query in the DAG please send them to me”. Smart right? To me, Graphsync is like a "batch Bitswap request".
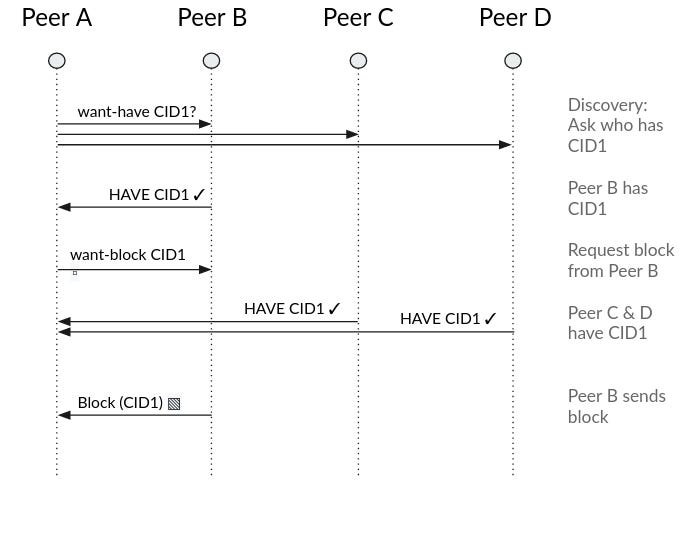
Beyond Bitswap
The current implementation of Bitswap has already shown impressive results speeding-up the discovery an exchange of content compared to “traditional” DHT content lookups, or even to centralized infrastructures (I highly recommend reading this post which describes how the teams of IPFS and Netflix leveraged IPFS as a peer-to-peer CDN to let nodes inside Netflix’s infrastructure collaborate and seed common pieces to neighboring nodes, helping make container distribution faster. Incredible, right? And one of the responsibles for this improvements is Bitswap).
All of this doesn’t mean that Bitswap can not be further improved. My feeling is that one of the first things we need to do in order to be able to better Bitswap’s current outstanding implementation is to understand what are the overheads of the protocol, and what is preventing us from exchanging content faster in IPFS. It is the discovery of blocks or their actual transmission? Could we devise better ways to store data in the network to ease the content discovery? Even more, we use IPFS for a great gamut of use cases that may require from the exchange of several small files, to the download of large datasets. Does Bitswap perform equally under these scenarios, or should we consider the implementation of a “use case-aware” content exchange algorithm?
To this extent, in the next few weeks I am planning to build a test environment to help us answer these questions in order to understand if together, and considering the results of this analysis, we can take Bitswap and file-sharing in P2P networks to its theoretical limit.
In short, a lot of exciting things are going on around Bitswap. I could keep writing about this for a few hours more, but I guess it makes more sense to keep this the first part of a series, and periodically share some updates and knowledge pills. Stay tuned!
Hey Alfonso, can I find this test environment somewhere if I wanted to play around with bitswap too?