
@adlrocha - Building a scalable monolith
The commoditization of the Cloud

Monolith or microservices? The eternal question many software engineers face when having to design and deploy their brand new system. You will find diehard followers for both approaches. Some will tell you that monoliths are the best thing you could have, as they are easy to deploy and maintain. Others will claim that monoliths are for “IT dinosaurs” and that they are hard to scale, look at the Googles, Amazons, and Netflixes of the world, they are all using microservices. The truth is that there is no “one size fits all” solution, and each architecture will fit different purposes, systems and companies. For Google’s scale, of course it makes sense to use microservices, scaling and maintaining a monolith would be a complete nightmare. However, for applications and platforms with a few thousand daily users, a monolith may suffice.
But I am not writing this publication to make an argument for or against monoliths or microservices, but to challenge our assumptions and raise the following question: with the recent technological advancements, can we finally design a “one size fits all” architecture able to support Amazon’s scale (OK, maybe Amazon is too much, let’s consider Slack), with the simplicity of deployment and maintenance of a “traditional” monolith?
“There is no industry consensus on whether either approach is strictly-better. Despite that ambivalence, there is general agreement of two points:
Monoliths that exceed some threshold will be broken apart eventually. At a large enough scale, only a service-oriented design is workable.
There are only two options. It’s either service-oriented or a monolith, and you must choose.”
The Current Landscape
A monolith is a server-side system that runs everything in the same place. A monolithic application is usually a single program that starts up, listens to a few ports for network requests from end-users, gives service to these end-users, and eventually terminates. Maintaining the infrastructure is easy, is just one server running an application. Scaling, on the other hand, may be hard. The fact that everything is in the same place means that launching a new replica of the application to spread the load between them may lead to inconsistencies or useless redundancy. Also, the code for a monolithic application is usually structured in the same repo, it is not divided in modules like is the case for microservices, where each service has its own repo. I don’t have a strong opinion on if this is good or bad, but it is what it is. An example of a monolithic application is the typical Django App we have all learned respect and love.
Microservices architectures are just monoliths that have been broken down into smaller pieces. Instead of having a Django App responsible for serving the frontend of your app, exposing a REST API to interact with the whole system, and talk to your database, you have a set of services: an API of user authentication, a service to serve the frontend assets, an API to process payments, and the code of each of them is conveniently structured and maintained in its own repo. The reasoning behind this alternative design pattern is actually very sound. By distributing the work among many different components, you make the system as a whole able to handle more requests than when we stuck all together in the same place. However, by doing so, we introduce more complexity, which requires more effort, and therefore often more people-power and more money. It is not the same to manage the infrastructure for a single big service, than for a bag of small interconnected services (potentially distributed).
“A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” -- Leslie Lamport
Some may argue, “but wait a moment, that makes sense for ‘traditional’ microservice architectures, but what about serverless functions”. Agree, serverless architectures simplify many of the complexities introduced by microservice architectures, but they also introduce new challenges. The gains you may gain for the ease of maintenance may be eclipsed by serverless difficult testing (now you don’t need to test each service of the application and their integration, but each function and their integration), potential vendor lock-in (we have Docker as the “standard environment” for microservices, but we don’t have this for serverless functions, each vendor has its own offer and tooling to manage this). Serverless architectures are moving towards that “one size fits all” solution, but they may not be enough.
And finally, we have the neo-monolith approach which divides the application into different services hosted in the same infrastructure (we get a cleaner code structure and an eventual simpler transition to microservices, but with the advantage of monolithic infrastructure management).
With this, we now have a clearer view of the current landscape. A lot has been written about the pros and cons of monoliths v.s. Microservices v.s. serverless. Take a look at this post, this one, or maybe this one for some interesting viewpoints on the pros and cons of microservices. But what have changed for me to consider our ability to build better architectures?
The problem with prematurely turning your application into a range of services is chiefly that it violates the #1 rule of distributed computing: Don’t distribute your computing! At least if you can in any way avoid it.
The New Additions to the Club
The three technologies that have made me re-evaluate our ability to build a “one size fits all” architecture for web systems are the following:
Web Assembly: My excitement about the possibilities of this new technology is well-known to all of you assiduously following my publications. I’ve written extensively about Wasm as a Universal Bytecode, Wasm as a docker replacement, and going towards a universal runtime with Wasm. One of the drawbacks I mentioned about serverless functions is the lack of a standard runtime environment, but the fact is that we may have it already, Wasm, and it may be the key to a new scalable and maintainable architecture. Actually, some companies such as Fastly are already using Wasm in their serverless proposals.
The Web3 stack: I get it, I am quite biased, but I really think web3 protocols are the future of the Internet in several respects, as I’ve also already mentioned in some of my publications. Someone looking to deploy their web platform nowadays needs to choose wisely the cloud provider where he is going to host his infrastructure as this may influence the availability and SLA of their application (as well as other concerns mentioned above such as vendor lock-in, etc.). We refer to the cloud as that global platform able to fulfill all our computational and connectivity needs, when in reality the cloud is a disjoint group of infrastructure providers capable of fulfilling these needs. When we talk about our Internet connection, we don’t care that much about the ISP that is giving us the access, because the Internet has become a commodity, this has not yet been the case for the cloud. Web3 stack protocols and the decentralization of the Internet is what is going to finally transform the cloud into a commodity. My feeling is that a commoditized cloud would finally bring us the “one size fits all” architecture we are looking for, as it will be supported by default by “the new Internet”.
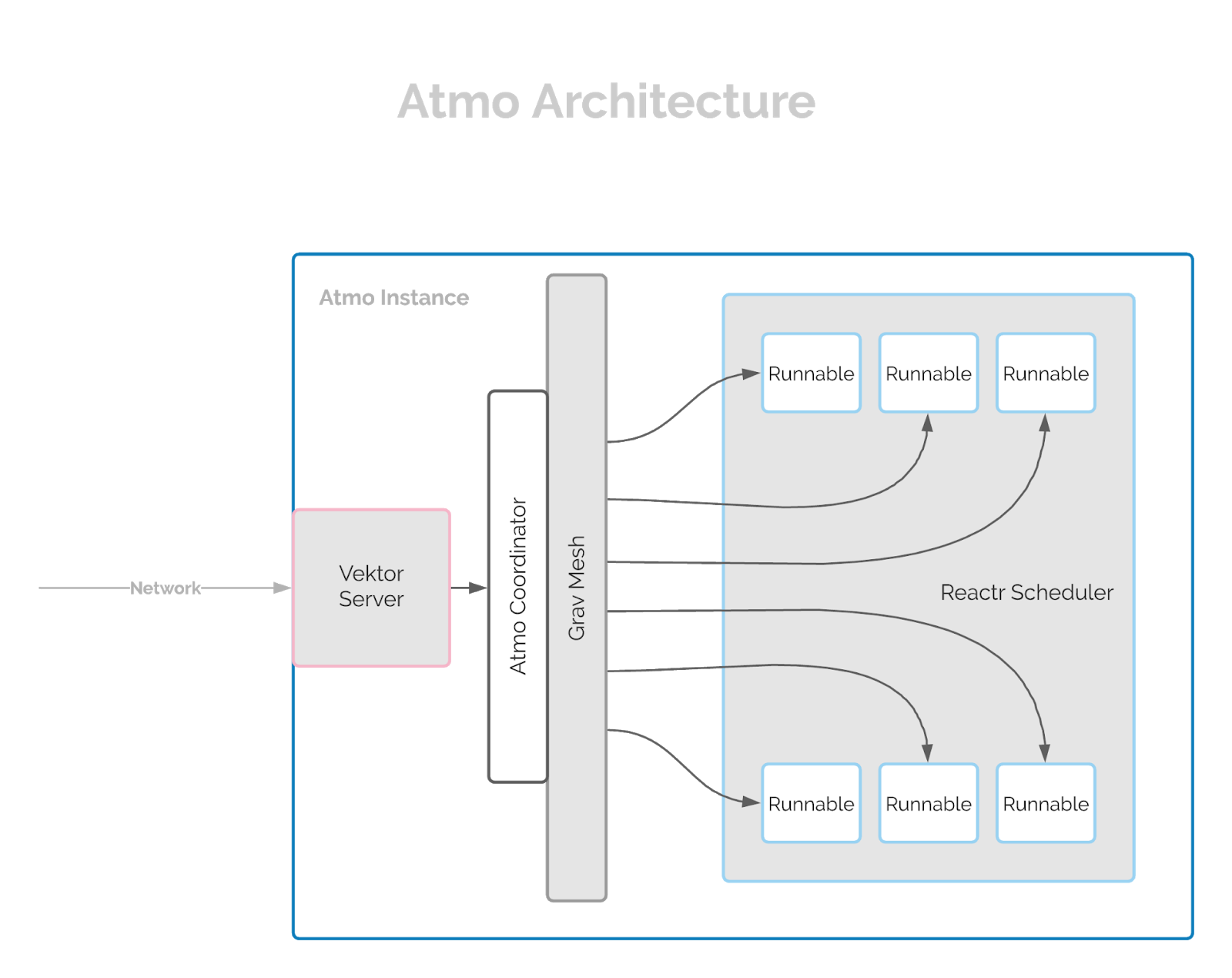
Suborbital Atmo: Atmo makes it easy to create a powerful server application without needing to worry about scalability, infrastructure, or complex networking. Atmo enables you to write small self-contained functions called Runnables using a variety of languages, and define your business logic by declaratively composing them. Atmo then automatically scales out a flat network of instances to handle traffic using its meshed message bus and embedded job scheduler. Atmo can handle request-based traffic, and soon will be able to handle events sourced from various systems like Kafka or EventBridge. So essentially, you deploy a serverless infrastructure as if it was a monolith. I’ve been tinkering with Atmo, and its underlying modules for some weeks now, and I think it is a great piece of technology and a good example of how this “one size fits all” solution over a decentralized cloud could look like. I won’t go in depth on how Atmo works (at least for now), but I highly recommend giving it a good look, and checking out this issue ;) (could this be the beginning of something big?)
If monoliths are hard to scale and microservices are too complex, then how do you design a system that can scale with your traffic and your development team without becoming a pain to operate, maintain and expand its functionality? Over the past few years, it has become clear that a middle-ground is needed. I don’t expect this solution to work for everyone, but most products aren’t serving the kind of traffic that really makes the microservice effort worth it. -- @coohix
Towards a “actual” global cloud
In my TWIL#2 from a few weeks ago I mentioned that I built for a hackathon a proof of concept of how I imagined computation over IPFS would work (you can check out the code here). This idea already glimpsed how a global cloud would look like. You run computations in the network without having to worry about who is running it, or where the resources are. Of course, a trustless model as such wouldn’t scale without an incentive system that rewards peers contributing their resources to keep the network running (especially if we want an SLA and certain guarantees, but lets leave this out of the picture for now).
With a decentralized network as IPFS already in place, why not trying to offer developers the ability to host applications scalable-by-design, and easy to maintain? IPFS is a decentralized content-addressable network, so it has CDN capabilities by-design. Peers looking to run some job (or get some file), will fetch it from its nearest neighbor (if possible), without having to worry about finding the server hosting the service, because resources in a content-addressed network are location-independent. All of these concepts could potentially make the “monolith v.s. microservices” argument outdated. Actually, almost a year ago I already wrote a publication explaining how a recent standard such as WebBundles were a perfect fit for content-addressable networks.
Changing the way the core of the Internet works can make decade old arguments outdated such as the architecture wars, and it all starts with the “actual” commoditization of the cloud through protocols that expose the cloud as a single global entity, not as a disjoint fight between different providers. Adoption is key for this change of paradigm to become a reality. All of this should translate into better alternatives for developers and users. Can Atmo over IPFS be the beginning of this “revolution”. We’ll see…