
@adlrocha - Form Before Data: The Real Bottleneck for Physical AI
The Tesla flywheel and why we won’t get the Humanoid butler anytime soon

A reader messaged me last week with a question about a topic that has been in my backlog for a few months now, AI and the physical world. The request was the following “Can you elaborate on the rate of adoption of AI for the physical world? We see [it] operating almost entirely in the digital realm. The Tesla FSD vehicles are examples of AI moving in the physical world. We are also beginning to see other machines such as humanoid robots move through space by interpreting the visual field. But these examples are still very uncommon.”
He’s right, and while “still very uncommon”, the field is making progress fast. We have AI that writes code, drafts contracts, and passes the bar, and we have a handful of cars and factory robots, and almost nothing in between. But my feeling is that the gap isn’t intelligence, I think the models and foundational technology is there. What we are missing is the right “body” and “senses” for the model to make sense of the world, and the data needed to teach it how to navigate it.
That’s the thesis I want to make the case for in this post. Tesla cracked self-driving first not because its models were the smartest (until quite recently they were using traditional visual pattern recognition models instead of using deep-learning end-to-end), but because the car was already the right shape to act in the world for their specific task. It rolls, it steers, it has somewhere to put cameras. The form of the robot and the actions it had to perform in the physical environment were already well-defined. Everything physical AI does next is a search for that same fit: the right form for each task, and the intelligence to drive it through a messy, imprecise, badly-lit world that no simulation fully captures.
Why the car came first
A car is a strange thing to call an autonomous robot, but that’s essentially what a self-driving car is: a machine that senses its environment and acts in it. And it turns out to be an unusually “easy” (big quotes) robot. It moves in two dimensions. It has four contact points with the world and they never change. It can’t fall over, it can’t drop anything, and the rules of the road are written down. Compare that to a hand picking up an egg, where success depends on grip force you have to feel rather than see, and you start to understand why driving fell first. The car was already the right shape for the job, and the operations it could perform and its core goals were well-defined. Similarly to how LLMs cracked coding first because there was an objective feedback loop to optimise, car was the obvious one (in retrospective) for AI in the physical world.
Everyone (I hope) that owns a car knows how to drive it. Tesla managed to ship an attractive EV that people would buy, drive, and collectively pull the real-world data required to eventually teach an artificial brain how to autonomously drive one of these robots with wheels. Having access to all of this raw data of the physical world in virtually all possible kinds of scenarios, environments and locations, is what has enabled Tesla to finally crack SFD.
Tesla’s fleet has now passed 10 billion miles driven on FSD, adding roughly a million miles a day. Since FSD v12 the system has been a single end-to-end neural network, vision only, with the old hand-written rules torn out. It learned to drive by watching the fleet drive.
Notice the order of operations. Tesla didn’t sell cars and then bolted on autonomy as a side project. The car was the data-collection programme. Every vehicle on the road has eight cameras recording how real people handle real roads in bad weather, and that stream is what trains the next model. They built the perfect sandbox environment and data flywheel to train their self-driving models. Waymo, with better sensors (because Tesla only uses visual sensors) and a smaller fleet, has spent years unable to (so far) out-engineer Tesla’s simple advantage.
One of the reasons why Tesla could build this flywheel is because the “body”, “environment”, and “rules” for these robots were pretty well-defined. You cannot collect ten billion miles of driving data without ten million things shaped like cars already driving around. Form is the precondition for data, not the other way round. That is the move every physical-AI company is now trying to repeat, and it is much harder when the task is folding laundry instead of staying in a lane.
If we treat Tesla cars as the first instance of autonomous physical robots, I think there’s a lot of learnings that we can extract and immediately apply to the field of robotics.
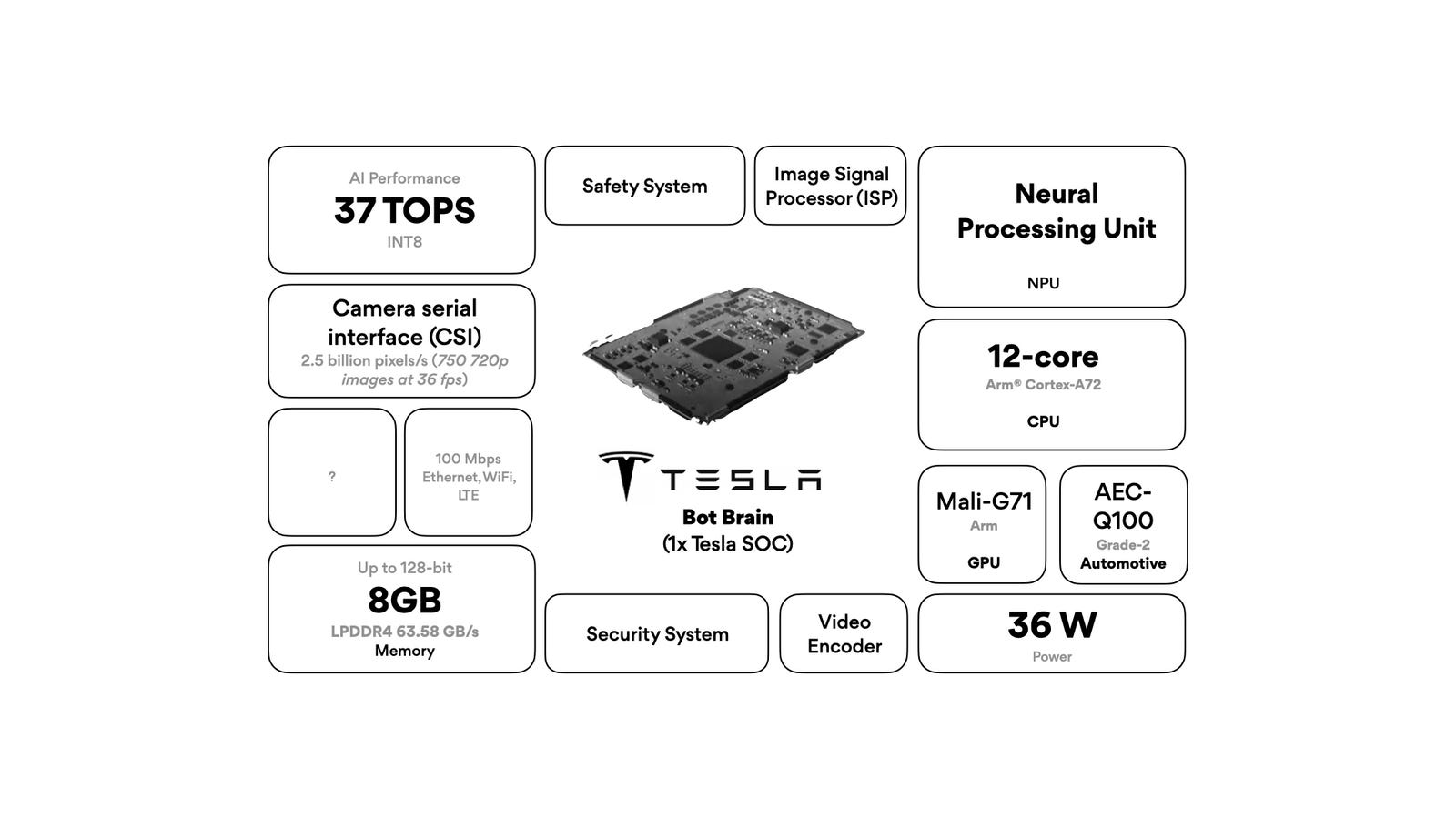
The two things a body still can’t do
If form is the precondition, the obvious question is why we don’t already have the right forms everywhere. The bodies seem to exist. Figure, Optimus and Unitree all walk, balance and grasp, and bipedal locomotion that took the field decades is close to a solved engineering problem. So what’s missing?
Two things, and neither is intelligence in the abstract sense. The model can already plan. What it can’t reliably do is feel, and what we can’t yet cheaply do is teach it the specific task. While we can consider a car like a “narrow body” for a “narrow task”, I feel like humanoid robots are a general-purpose form factor to whom we could teach a great gamut of tasks that we already do ourselves. We just need to teach them how we do it.
Driving is a vision problem, and vision is the sense AI is best at and one of the first ones it was able to crack (do you remember the amazing things that convolutional neural networks, a.k.a CNNs were, able to do a decade ago?). Folding a shirt is not. It needs touch, the kind that adjusts grip force when a fabric starts to slip, and dexterous tactile hands are the part of the body that still lags the rest. The economics show where the difficulty sits: actuators alone run 30 to 40% of a high-end humanoid’s bill of materials, a single high-torque actuator costs thousands, and there are twenty or forty per robot. A car needs a steering rack. A hand that works by feel needs a torque-controlled actuator at every knuckle, and the supply chain for those parts is not built for volume yet. The right form for manipulation is genuinely harder to build than the right form for driving. The number of actuators that the models need to be able to activate for a specific action is significantly larger than in the case of a car.
Then there’s teaching them how to perform a task accurately. Large models learned language by reading the internet, text humanity had already written and left lying around for free. There is no equivalent corpus for physical action in the physical world in almost every possible environment and scenario (the kind of data corpus that Tesla collected through more than a decade of people driving their cars). No website stores the exact sequence of joint torques and micro-corrections in threading a cable behind a desk or lifting an egg without crushing it. That data has never been recorded and translated in the “senses” incorporated into these humanoid robots.
The workaround that many have tried is to use simulations of the physical world: like in RL environments, you let the model run a billion virtual attempts overnight to train. Tesla also did this for some years. It works right up to the sim-to-real gap, the point where the policy meets a real machine and the friction is slightly off, the actuator lags a few milliseconds, and the object deforms in a way the simulator never modelled. For humanoids that gap is wider than for four-legged robots, because more joints and more contact mean more ways for a small error to compound into a fall, and there is no general fix. Every team patches it by hand.
Put the two together and you get the real state of physical AI in 2026. The model is smart enough and the technology is there. The body can move. What’s missing is a body that can feel its way through a task it has never seen, and the mountain of real-world demonstrations needed to train it. That is why all those cool slick backflip videos from robots are just a demonstration of the form factor and specific actions being cracked, not a deployment. While we are getting close, we still are teaching these general-purpose robots how to perform specific tasks in different scenarios of the physical world.

Humanoids in 2026
The humanoid is the form that gets all the attention, because they are cool and they can move like us. With all that said about how hard manipulation is, the deployments are real, more real than I expected when I started looking.
Figure has robots on the line at BMW’s Spartanburg plant, running ten hours a day at better than 99% placement accuracy across more than a thousand operational hours. Tesla is targeting 50,000 Optimus units in 2026 inside its own factories, and Unitree will sell you a G1 today for around $16,000, the Model 3 of robots: cheap hardware at volume, worry about generality later (I see the “Tesla pattern” here of deploying the platform that enables data collection at scale).
But notice what all three have in common. The tasks are narrow: load this panel, place this part, etc. These are factory jobs in structured spaces, the closest a robot gets to a car’s nice clean lane. The robots are supervised, single-purpose, and a long way from the general-purpose machine that tidies your house. Map them onto the Tesla timeline and we’re roughly where the fleet was a decade ago: the hardware is out gathering experience, the autonomy is years of data away, with the caveat of the form factor.
And here’s the thing the humanoid hype obscures: for most of these jobs, the metal human is the wrong form. They could be using robots that are closer to what factory robots look today, but by using a humanoid form factor, we have a general-purpose platform that can be taught any kind of task that a human could do.
The robots that are working do not look human
Robots have been around for decades. China runs an operational stock of around two million industrial robots, and Xiaomi builds ten million phones a year in a lights-out factory at 81% automation, but all these robots operate through a specific script, the logic is hardcoded. The task and the operation needs to be clearly hardcoded and implemented, like it was the case of the early Teslas.
The thing actually changing in 2026 is that we are starting to see robots whose behaviour comes from a learned model instead of a fixed program, machines that can handle a situation nobody scripted in advance. That is what “AI for the physical world” means to me, and the most successful instances of this so far do not wear a humanoid shape. It shows up first in the jobs where the body is simple but the world is messy, which is exactly where old automation couldn’t go.
Agriculture is the clearest example. A fruit-picking arm sounds may seem something that can be implemented with classical automation until you look at what it has to do: find a ripe strawberry behind a leaf, under changing light, half-occluded by another berry, and decide in real time whether to pick it. That is a perception problem, and it’s being solved with the same deep-learning vision stack as everything else. Recent harvesters run models like YOLO-based ripeness detectors trained for occlusion and light changes in real orchards, and dedicated ripeness networks that judge a blueberry the way a picker would. The arm is dumb. The eyes are not. John Deere’s autonomous tractors carry a sixteen-camera vision rig and a perception model that reads the field as it goes, rather than following a pre-mapped line. The number of fruit farms running autonomous harvesters jumped from 950 in 2021 to over 4,300 in 2024, and that curve is bending now because they can now interpret the real world, not because anyone invented a new arm.

The deeper shift is the arrival of foundation models for action, the physical-world equivalent of GPT (something I was completely unaware of). These are vision-language-action models: you give them camera frames and an instruction in plain language, and they output motor commands. RT-2 was the first to show real generalisation, jumping to 85% success on objects it had never seen, versus 60% for the previous generation, by training on internet images and robot trajectories together. π0 is a 3-billion-parameter action model that runs fast enough to control a real arm in real time, and by 2026 π0.6 and Google’s Gemini Robotics are the state of the art, with Alibaba’s open-weight Qwen-RobotManip arriving this month and topping the generalist benchmark, the same move they made for LLMs they are trying to make in robotics, open-sourcing the frontier. Before, the question was “can a learned policy work at all?” and how we are turning into asking ourselves “how do we make it reliable in the wild?” With foundational models for robotics like the latest ones from Qwen, the intelligence is becoming portable, and the body is becoming the interchangeable part.
So to directly answer the question from our reader, the robots already running at scale aren’t AI, but the foundation for it is being built. The robots that are genuinely AI, the ones reading a vine or grasping an object they’ve never seen, are real but young, and they’re appearing form-first: a simple, task-shaped body wrapped around a perception-and-action model that does the hard part. Pre-programmed automation needed a world held perfectly still. The new robots are the first that can cope with a world that won’t.
Where’s the value accrual right now?
If physical data has to be manufactured, the most valuable thing you can build is a platform that enables this data collection at scale.
The most vivid version of this is almost funny when you first hear it (the videos I’ve seen about this are extremely disturbing): companies are paying people to do their own chores on camera. DoorDash launched “Tasks” in March, paying drivers up to $25 an hour to film themselves doing housework, and a startup called Micro1 has a thousand people across sixty countries wearing iPhones strapped to their heads while they cook and clean. China is running the same playbook at state scale.
This is the Tesla flywheel, with a human where the car used to be. You can’t scrape demonstrations of physical work, so you pay humans to generate them. The car was the sensor. Now the person is.
The higher-fidelity version of the same idea is teleoperation: instead of filming a human, you have a human drive the robot directly, so every recorded action is in the robot’s own body, with real contact and real error-recovery and zero gap between the demonstrator and the machine. It’s the fastest-growing category of robot training data this year, and it’s the cleanest expression of the whole thesis: humans in the loop now, autonomy later. There are even VCs that are forming their whole robotic thesis around investing in companies that are focusing on building this teleportations as platforms for physical world data collection:

What this approach provides is not only to have a human expert solving a task remotely, but also to iterate on the right body form to solve the task, and of course collect real world data to then train the models.
The cost of everything in the physical world goes to zero?
According to the wide-spread narrative, knowledge work is collapsing fast. Opus is commoditising coding, open-weight models like GLM are now commoditising the frontier labs that did the commoditising. The barrier to producing a working piece of software, a passable legal draft, a defensible piece of research, has fallen close to zero. Anything that runs on a computer, the argument goes, is heading the same way, and physical work is next on the list once the robots arrive (faster even if it has ever been available on the Internet).
Software collapsed fast because it was software. Bits copy for free, so once a model can do the work, distributing that ability costs nothing. And the training data already existed: decades of code on GitHub, decades of writing on the open web, sitting there waiting to be ingested. Free distribution plus pre-existing data is a recipe for AI success, virtually unlimited data (although I would claim that we are running out of it).
The physical world has neither property. You can’t copy a robot for free, and there is no GitHub of physical actions to train it on. So yes, the same collapse is coming for physical work, but following classical physics and not the speed of the light like was the case of software (sidenote: many of you will assume that this sentence comes from an LLM, but I wrote it myself, and I am so proud of it that I am leaving it, and I don’t give a shit what you think, this is still human-written). It will be slower, and the slowness is structural. It’s always harder (and slower) to do things in real life, when you interact with a real environment under classical physics.
And it won’t arrive all at once. The “physical work goes to zero” framing misses that the collapse will be task by task, ranked by two things: how easy the right body is to build, and how messy the world is allowed to be. The most structured work already went to old-style automation that needs no intelligence: the caged factory line, the warehouse conveyor. Semi-structured outdoor work like fruit-picking and grid inspection is falling now, over this decade, because the body is simple and the vision models have finally caught up to the mess.
The unstructured human environments, the home, the hospital ward, the building site with people walking through it, are last, and “last” here means well past the three-year window the reader asked about. Electricians and plumbers are safe for longer than software engineers, not because their work is more skilled, but because their work is harder to give a robot the right body for, and impossible to scrape off the web. And beware, because you can already see real deployments in China that I mentioned above (I highly recommend everyone to search for China and robots in youtube to see the cool stuff they are building, from cleaning robots for solar panels, to last-mile delivery trucks).

But the barrier will fall eventually. That is the part I don’t want to undersell. Every constraint I’ve described in this post (no internet of physical actions, brittle hands, the sim-to-real gap, the actuator supply chain) is a problem with a known shape, and known-shape problems get solved on long enough timescales. The chore-filming gig economy is ugly, but it is a corpus being built. Teleoperation is awkward, but it is the cleanest demonstration data we’ve ever had. Qwen’s open-source action model is half marketing, but it is the first credible attempt to skip the collection step. The barrier is high. It isn’t infinite. The interesting question is what happens in the meantime.
So what’s next?
To answer the reader’s question, I think we are in the platform-building phase of physical AI. The platform phase is where the infrastructure for collecting data and iterating on policies is being assembled in public, and almost everything you see in a press release is really a wrapper around that. The teleoperation rigs are platforms. The narrow harvesters and tractors are platforms. The chore-filming apps are platforms. Even the foundation-model labs are platforms in disguise: their real product is the loop that turns demonstrations into policy, and the robot is a customer of that loop. The next three years are not about robots getting good at jobs. They are about building the sandboxes in which robots and the humans who work with them can figure out, slowly and in public, what those jobs even look like. We are going to start seeing some real deployments, but they won’t be ready to scale yet, and they will be focusing on becoming the sandbox to collect the data required to improve their operation.
My three-year call is that we don’t get the general humanoid butler. We get a widening fleet of narrow, AI-driven machines, each the right body for one job, wrapped around a learned policy that does the hard part: the strawberry-picker reading a vine, the tractor reading a field, the teleoperated arm running a π0-style action model. Each is also a data-collection sandbox for its own domain, harvesting the demonstrations that slowly teach it to handle the mess, and teaching the humans in the loop how to work with it. The general humanoid is the destination. A fleet of narrow, right-shaped platforms feeding their own flywheels is the road. The durable value sits not in any one body but in the portable intelligence on top, and in the loop that connects it to the humans who, for now, still know how the job is actually done.
I am curious to see what we are going to see companies building in the next few years, and the market’s response to it. I genuinely don’t know if the simulation, teleoperation or real data collection play will be the one that finally cracks autonomous robotics. Anyone working with robots that could give some colour to my predictions? I hope to get someone in the comments or my inbox, but if I don’t, see you next week!