
@adlrocha - How I built an IPFS crawler with libp2p
And lessons learnt

I already mentioned in my publication dedicated to my financial dashboard side-project that, for me, the most effective way of learning something new is embarking myself in a “pet project” that motivates me enough not to abandon it halfway through. I force myself to develop the project using the new technologies I want to learn so in the process I end up with a brand new side project and a whole bunch of new skills. The financial dashboard was an excuse to learn GraphQL and ReactJS (to be honest, since then I’ve been actively using ReactJS more and more, so it paid off). Today I am going to share my “excuse” to sharpen my skills on libp2p and concurrent programming in Go (with goroutines, waitgroups, locks, the usual): an IPFS crawler built in libp2p.
Setting the context
It’s no secret by now that I’m fascinated by p2p, distributed technologies, and their future (and not so future) impact in the architecture of the Internet and society in general. One day I was thinking about how it would work to deploy a p2p network to orchestrate in production all the devices in a federation of data center when I realized something: data center infrastructures are highly monitored in order to detect any minimal deviation from the baseline operation of the system. In traditional (and centralize) infrastructures analytics are “simple”, you can have a central monitoring system to collect every single metric from your infrastructure, because you are the owner and manager of it. But when you have a decentralized system owned by several entities where you only operate a small part of the network, how can you monitor its overall status and ensure that the systems is working as it should? You only keep a local view of the network, and you want to learn about the status of the full network. Monitoring and analytics in distributed, unstructured, and self-organizing networks is hard, especially without a centralized infrastructure to orchestrate everything. So with the excuse of deepening on concurrency and libp2p (and triggered by some external circumstances), I decided to start exploring this problem on a small scale.

Counting nodes
I chose to start small but ambitious. I wanted to explore the problem in a real network, so setting up an 8 nodes network in my local machine in order to experiment would have been cheating. So I decided that I was going to try and collect some metrics from one of the largest p2p networks out there, IPFS. Specifically, I was going to try to monitor the total number of nodes active in the network, and its daily churn (a ratio of the number of nodes that have left throughout the day).
A first search on the problem showed several results of academic papers attempting to map the IPFS network, and existing implementations of libp2p network crawlers. So others had already approached this problem before. It was my turn now to see if I managed to follow their steps.
Enough with the preambles I took a blank page of my notebook, I started doodling a potential design for my tool, and I ended up with the following architecture for my crawler:
The crawler would be conformed by three distinct processes: the crawler process (in charge of random walking the DHT in search of connected nodes —more on this in a moment—); a liveliness process (responsible for checking if the nodes already seen where still alive); and the reporting process (outputting the current state of the analysis, nothing fancy).
To crawl the network I chose a pretty unstructured scheme, a random walk of the routing DHT. Crawlers would chose a random node ID and it would ask the network “hey, guys! give me a list of the x nearest nodes to this folk”. The crawler would then try to make an ephemeral connection to these nodes to see if they are up, and if they are add them to the list of active nodes in the network. In this way we “randomly traverse” the network in search of active nodes. I could maybe have used a more structured search where instead of choosing a new node ID randomly I took all the peers from my k-buckets, see if they were alive, request a list of peers from the k-buckets to these nodes and so on recursively. My first implementation followed this scheme. It may have ended up being more accurate, but it felt slower than the random approach.
The random walk searched for active nodes in the network, but I required a way of checking if these nodes were still alive or if they had left the network. This is the purpose of the liveliness process. This process is dead simple, while the crawler searches and updates the list of active nodes, this process loops through the list of active nodes and tries to make ephemeral connections with them to see if they are still alive.
Finally, the reporting process just takes the stored metrics and periodically shows them. Initially, the only metrics I collect from seen nodes are: the moment it was last seen, and if it is behind a NAT or not. This last metric is pretty important to check if a node is still alive, because even if the ephemeral connection fails it may be because he is behind a NAT and not because he is out. So that’s why we need to know beforehand in the node is behind a NAT in order to know how to identify leaving nodes.

Show me the code!
You can find the code for the tool in this repository: https://github.com/adlrocha/go-libp2p-crawler. The README file includes some information about the design decision and the implementation, but if you are just curious to see the tool working you can clone the repo, compile the code and run it to see the magic happen:
$ git clone https://github.com/adlrocha/go-libp2p-crawler
$ go build
$ ./go-libp2p-crawler -crawler=<num_workers> -liveliness=<num_liveliness> -verboseThe -crawler and -liveliness flags let you choose the number of goroutines dedicated to searching new nodes, and checking if nodes are still alive, respectively.
For those of you who want to know a bit more about how I implemented this tool, let me walk you through its implementation:
The first thing the system does when starting up is starting a new libp2p node for each crawler process that wants to be started up. These nodes then connect to the IPFS bootstrap nodes. When a node has been bootstrapped it start searching for new nodes.
A node can run only the crawler process or it can run the crawler and liveliness process simultaneously according to the number of crawlers and liveliness chosen for the execution (bear in mind that crawler nodes are designed so that they can’t be only performing liveliness checks, so you can never have more liveliness workers than crawler workers. This is a design choice and could be easily modified).
To store the data about nodes seen, actives nodes in the network, etc. I chose to use LevelDB. The system has several goroutines writing in the same data storage, so using LevelDB was a pretty straightforward way of avoiding data races. After some initial tests, I also chose to use locks in order to explicitly remove any potential data races.
The reporting process only shows information about the number of nodes seen and that have left today, the number of active nodes in the network (at least our view of it), and the daily churn. I am also storing information about when was the node last seen, and if he is behind a NAT so I could also compute the rate of nodes behind a NAT, or a rough estimate of the average time a node stays connected. I also thought about exploring other metrics such as the average RTT with the rest of the network, the available transports in the seen nodes, and other interesting metrics about the network, but I chose to focus on simple metrics for the moment (crawling was hard enough to be worth the endeavor).
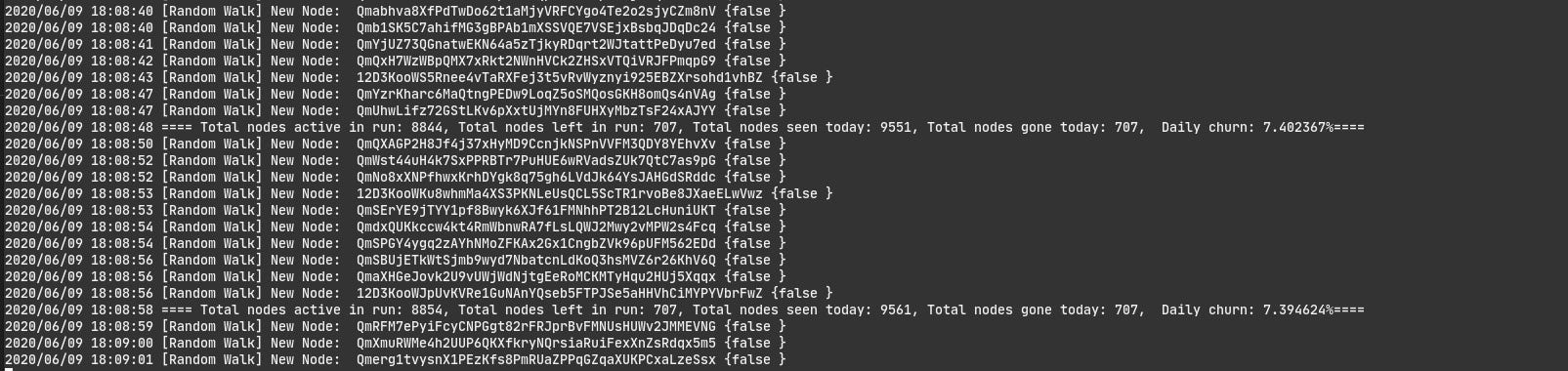
Sample execution of the tool
After long executions of the tool I started experiencing how the number of total nodes leaving the network was being restarted when reaching ~500. This bug was really messing with me, I did several isolated tests to the counters, to all the goroutines independently, until I chose to make an alternative implementation without LevelDB (that you can find in the branch feature/noLevelDB of the repo). With this alternative implementation the problem was solved and, you know what was happening? The structure I used to store the data, and the fact that in the liveliness process I had to make use of an iterator to loop throughout the data was messing with the synchronization. I was accounting for additional nodes and restarting counters when I shouldn’t. Another reason why I chose to use LevelDB was to persist the list of nodes seen, but due to the bug, and considering that I could use other less complex schemes to persist the data, I didn’t invest more time on trying to fix the bug for this post (although is something I will definitely do when I find the time).
Wrap up!
To be honest, I’ve had the time of my life playing with this project. I’ve said it a few times in this newsletter but let me do it one more time, I wish I could make this my full-time job! I would love to know your feedback if you test the tool. According to your feedback it maybe make sense to grow the project and actively maintain it. For the meantime, after going a bit deeper into libp2p, I came up with a few more ideas to explore, and I have already started a new “quick and dirty project” to learn something new. The next one combines WASM, libp2p and Rust. Stay tuned to see the results (depending on my availability in the next few weeks I may publish the results in a month or so). See you soon!
Hello it would be interesting to maintain an index of publicly found projects and known namespaces this could be navigable Do you have any examples ruining this on a free tie cluster. just need to make a new google account and run for 3 months 100$/month then shutdown see what we got