“On modern versions of macOS, you simply can’t power on your computer, launch a text editor or eBook reader, and write or read, without a log of your activity being transmitted and stored. It turns out that in the current version of macOS, the OS sends to Apple a hash (unique identifier) of each and every program you run, when you run it. Lots of people didn’t realize this, because it’s silent and invisible and it fails instantly and gracefully when you’re offline, but today the server got really slow and it didn’t hit the fail-fast code path, and everyone’s apps failed to open if they were connected to the internet.”
The other day I came across this article from where I extracted the paragraph cited above. I don’t know about you, but for me this is really terrifying. The fact that you are sending this information to Apple servers periodically, not only means that Apple knows which of their apps you are using, but also the time of the day, and from where you are using them (you send this data to Apple’s servers using an Internet connection, so they potentially track your IP and thus your localization). With these three simple data points Apple now is able to know when you are working, from where you work, when you go home and, if you like to read a book a while you take a dump, they may even know a lot about your bowel movements.
And all of this comes from a company that supposedly respects our privacy. It may actually be true that they protect our privacy, but I wouldn’t personally feel comfortable with them having all of this information about my bowel movements (I use Linux, so my shit is safe!).
In any case, the fact that we are sending any data to Apple servers without us knowing is worriesome enough. Even more, the fact that someone with good understanding about the tech under the hood had to reverse-engineer a system to fully understand what what was happening, and to what extent his privacy was in risk, is a complete shame. To me, this is one of the many reasons why open source needs to exist. Software should be trustless.
We need open source software
So you buy your brand new MacBook Pro, and you don’t agree with the values of the Big Tech. You use open source alternatives to all the applications you need on a daily basis. Now you feel more confident about your privacy’s protection than when you used Google Drive, and Slack. You are self-hosting your own OwnCloud, and using Matrix and Signal for your communications. Only to end up reading that after all the work you’ve been doing to protect your privacy, your own OS is leaking data about you. And what is more worrisome, you don’t even know the exact data you are leaking. At least when you use Google or Facebook you “kind of” assume that you are selling your soul.
The advantage of using open source software is not only the ability to freely modify or improve the code without having to ask permission to its creators. Or the ability to be able to fix bugs yourself. But the recomforting feeling that there are a lot of people smarter than you reading that code and validating it so that if something fishy seems to be happening under the hood they just have to go to the code, which is the “bearer of the absolute truth”. So Apple can claim to be privacy-respecting, but who is watching over this?
I am of the opinion that if we really want to own our data and our digital life we need to go “full open source”. I don’t expect average users to understand or even have a look at the code of all the software they use, but knowing that it is public and that smarter people than us are verifying it and making it better makes me sleep more peacefully.
Of course, a publicly available base code has its own risks. It is public both, for those aiming to make it better, and for those trying to hack it and take advantage of it. Many private software companies may choose no to open source their code not only so that “they are not copied”, but to have security by obscurity (i.e. if you don’t know what is inside it is harder for you to find an attack vector). The Apple data leak example from above is the perfect illustration to understand the concept of security by obscurity (even if it has nothing to do with security). Apple’s code is not open source, so the only way we have to know the data that we are sharing is inspecting the packets that leave our device (one can’t resort to the bearer of the absolute truth, the code, because it is hidden).
“So are you suggesting that we should all use an open source operating system?” Not only. The perfect scenario would be one where we use open software and open hardware. To finish making my point, I will support myself on how the people behind Enarx explain the problem they are trying to solve:
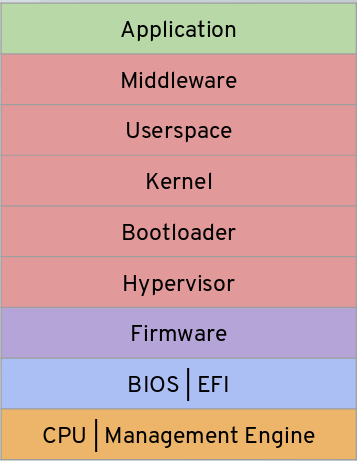
When you run software (a “workload”) on a system (a “host”) on the cloud or on your own premises, there are lots and lots of layers. You often don’t see those layers, but they’re there. Here’s an example of the layers that you might see in a standard cloud virtualisation architecture. The different colours represent different entities that “own” different layers or sets of layers.
Here’s a similar diagram depicting a standard cloud container architecture. As before, each different color represents a different “owner” of a layer or set of layers.
These owners may be of very different types, from hardware vendors to OEMs to Cloud Service Providers (CSPs) to middleware vendors to Operating System vendors to application vendors to you, the workload owner. And for each workload that you run, on each host, the exact list of layers is likely to be different. And even when they’re the same, the versions of the layers instances may be different, whether it’s a different BIOS version, a different bootloader, a different kernel version or whatever else.
The reason we care is not just the different versions and the different layers, but the number of different things – and different entities – that we need to trust if we’re going to be happy running any sort of sensitive workload on these types of stacks. I need to trust every single layer, and the owner of every single layer, not only to do what they say they will do, but also not to be compromised. This is a big stretch when it comes to running my sensitive workloads.”
“The number of different things – and different entities – that we need to trust if we’re going to be happy running any sort of sensitive workload on these types of stacks.” And this is the key for our matter also. Our personal data is sensitive, a we should be able to use trustless software. Using a lot of layers of proprietary software makes us dependent on several entities. We need to trust them. It has its advantages, of course, but it also has its trade-offs, if not why would it be Gmail free then?
Don’t get me wrong, it is great that you are using open source software in any of these layers, from the firmware to the application, but if you really want to minimize your dependency on external entities (and their potential misbehaviors) you need to go open source all the way, from hardware to application.
But is that even possible? It is! Let’s see some examples of open source projects from the lower levels (because from Linux to the top the alternatives are well-known):
MuditaOS: A Beautiful and Minimal Open Source Mobile Operating System for Feature Phones.
Tuxedo Computers: Open source to the Bio (let me tell you that I’ve been using a Tuxedo Computer for six months and I couldn’t be happier).
And even open sourced GPUs (this is a research project so don’t expect this to become something in a while).
Finally, I highly recommend this article on the obscurity of current System On Chip designs and implementations. And then you can easily expect this kind of things happening.
Use the Internet like someone is watching you!
I have been having this feeling more and more the past few years, like someone is spying on me while I surf the Internet. We are coming back to the times of ARPANET when you had to be careful what you shared through the network because everyone could easily tap the wire. I don’t think open source will completely fix the problem and remove this feeling, but it can definitely have a critical role to make this happen.
There is a lot to figure out to achieve an “all open source digital world”. We always discuss the technical dimension, but how can we design sustainable business models for open source software companies? OK, there are several open source companies making a living with open source software already, but how would this work when everything is open source. Where would the competition come from? It is an interesting thought experiment to leave for some other day.
Final note: I’ve been receiving messages from many of you asking for me to come back to the publications on Sundays. Looking at the stats it is quite clear that you prefer reading me on weekends even if the email is sent on Thursdays, but I would love to hear your thoughts. So send me a quick message with your preferred day, and who knows? Maybe next week I come back to our beloved Sundays. In any case, see you next week!
Re: how can we design sustainable business models for open source companies, I came across one really intriguing model a few weeks ago: https://actualbudget.com/ , a local-first family budget app that offers cloud sync. $4/month subscription, which is low enough for most people to tolerate for an app that meets a real need. They talk about needing to fund continued development to keep the app relevant and useful, but I also feel like that $4/mo cloud sync is justification enough to satisfy most people.
I think that if this app were open-source from top to bottom, yes, a few people would try to run their own cloud sync server. And maybe there would even be the danger of rival companies using the same stack to run their own business and take money away from Actual. But I also think that the digital music stores of the world have shown that most people will pay for convenience. Thats why iTunes won the fight against Gnutella and BitTorrent -- because it was a no-brainer. Cheap, accessible music without spyware, missing tracks, weird filenames, corrupted data, or three-day download times.








Re: how can we design sustainable business models for open source companies, I came across one really intriguing model a few weeks ago: https://actualbudget.com/ , a local-first family budget app that offers cloud sync. $4/month subscription, which is low enough for most people to tolerate for an app that meets a real need. They talk about needing to fund continued development to keep the app relevant and useful, but I also feel like that $4/mo cloud sync is justification enough to satisfy most people.
I think that if this app were open-source from top to bottom, yes, a few people would try to run their own cloud sync server. And maybe there would even be the danger of rival companies using the same stack to run their own business and take money away from Actual. But I also think that the digital music stores of the world have shown that most people will pay for convenience. Thats why iTunes won the fight against Gnutella and BitTorrent -- because it was a no-brainer. Cheap, accessible music without spyware, missing tracks, weird filenames, corrupted data, or three-day download times.