
@adlrocha - Performance Best Practices in Hyperledger Fabric III: Protocol and Chaincodes
The "Fabric Into Production" Series (Part 3)

Time flies, and we are already in the third part of this series. After setting the context of the analysis, and learning how to make the most out of our infrastructure and the Fabric architecture, in this publication we’ll go through ways to fine-tune Fabric’s core protocol, and we will have a look at one of the matters that gave us more headaches in our analysis along with the infrastructure, the correct design and implementation of chaincodes
Protocol, do not touch (at least for us)
Some of the papers we read in our study of the state of the art proposed modifications in the core protocol of Fabric to increase its performance. Many of them were interesting enough to consider their implementation, and a few other have even been included in Fabric’s roadmap and added to the protocol in new releases. In our case, we chose not to touch at all the core protocol. We needed a Fabric version ready for production, this meant having an operations team responsible for ensuring the SLA of the system. There are companies out there offering support exclusively over Fabric’s official code (or their own enhanced flavor). In any case, no one would give us support to our very own fork of Fabric. Even if we had good ideas to enhance its performance, adding our own modification over Fabric’s base code would mean forking the official code and building a dedicated team to maintain this fork and keep pace with the official releases or, on the other hand, dedicating a team to contribute to Fabric’s source code. Unfortunately, both of the option were unfeasible at our stage, so at this layer we decided not to touch anything (so we were eligible for external support and we could benefit from the great talent in the Hyperledger community), and only fine-tune all that we could.
The first thing we learned the hard way (although it was a no-brainer) was that the version of Fabric you use for your network matters in performance. Every new release adds noticeable performance improvements. All our analysis were done over Fabric 1.4.4, however, we started our Fabric adventure back in version 1.1. My suggestion would be to use a version later than 1.3 (where important performance improvements were included). The best way to know the kind of performance improvements to expect in each version is to look at Fabric’s Jira and inspect its roadmap. After a quick look you will be able to get a glimpse on the works being done around this matter.
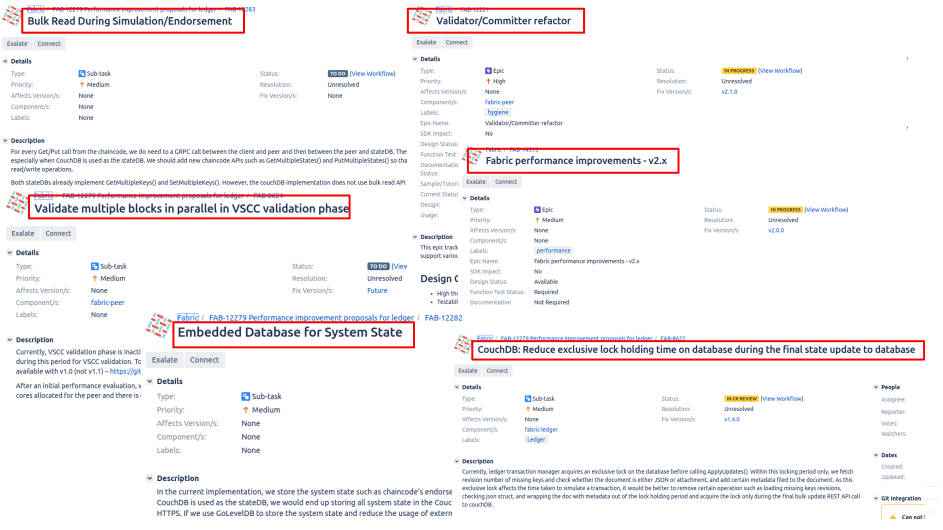
As already mentioned, our analysis was done over Fabric 1.4.4, but we are already planning our transition to version 2 (so I may have to update this analysis for this new version). Again, a quick look to the release notes of version 2 let us predict some improvements to the results of our analysis. The use of Alpine-based docker images may reduce the amount of infrastructure required for the Fabric deployment; and the use of caching in the state database is good news for performance, as it minimizes the annoying delay in which we incur every time we use a GetState/PutState operation and we need to communicate with CouchDB to manage some data.

But enough talk about versions. I said we couldn’t modify the core protocol, so what can we fine-tune then (apart from choosing the correct version) at this layer? Well, using data from the study of the state of the art mentioned in Part 1, and as a result of our own experience after so many tests, we draw the following conclusions:
After so many tests with a different number of organizations and several endorsing policies, we realized that the most expensive operation in a transaction’s life cycle is the validation of signatures. Consequently, the less signatures required for the endorsement process, the better the performance and the overall transaction throughput of the network. According to the use case, it may not be possible to limit the number of endorsing signatures, but it is useful to, at least, understand that we will incur in a cost for every additional signature we include in the endorsement of transactions.
As stated in the state of the art, to increase the performance of peers we can maximize as much as possible their parallel execution accommodating the GOMAXPROCS to the number of threads available in their underlying infrastructure (i.e. fitting the execution of software to the underlying hardware). This paper has a perfect explanation of how to do this.
Another thing we realized from our tests was that the more a peer had to interact with CouchDB in the execution of a chaincode, the worst the performance. This was due to the communication overhead between the peer and CouchDB, and when a lot of data needed to be retrieved from the database, the time required by CouchDB to access this data increased dramatically. The retrieval problem can be minimized by fine-tuning CouchDB’s cache strategy. This problem is already enhanced in version 2 with the cache of the world state, and it was already approached and improved in version 1.4 with the introduction of bulk operations between peers and CouchDB.
Finally, a configuration that can be easily adapted to our specific use case to improve our overall throughput and transaction delay is the block size (number of transaction per block), and the cut timeout (maximum time for the generation of a new block). If your use case has high load requirements it is better if you include a high number of transactions per block, as the cut timeout will never be reached, and blocks can be filled with a large number of transactions. However, with low loads it is better if you set a small cut timeout, so blocks are generated at a high rate even if they don’t fill of transactions. For general purpose networks as ours we realized that the default configuration of a block size of 10tx/block and a cut timeout of 2 seconds offered good results.
Learning in protocol
The version of Fabric you choose for your deployment significantly matters in the network’s performance.
Some configurations in Fabric’s protocol may be adapted to enhance the overall performance of the network according to the specific use case.
Chaincodes, the core of applications
Let me get this clear from the beginning, how you implement your chaincodes significantly affects your performance. When we were designing our chaincodes we were more focused on their functionality than in performance. Unit tests were passing, integration tests were passing, but when we started our load tests things started to break. A lot of issues started to arise with high loads. After applying all the good practices already mentioned in the lower layers, the transaction throughput of the network when using one of our simple chaincodes fell dramatically, and our peers were continuously returning a MVCC_CONFLICT_ERROR and a MVCC_PHANTOM_ERROR. What the hell was happening? Spoiler alert! We weren’t designing our chaincodes data model correctly.

Multiversion concurrency control (MCC or MVCC), is a concurrency control method commonly used by database management systems to provide concurrent access to the database. What was happening in our case? The high rate of transactions was causing two transaction to be attempting to write the same key in the ledger at the same time, or to use outdated source versions of its state to update the ledger. Thus, the MVCC conflict. And what about the MVCC_PHANTOM? It is the equivalent error when using CompositeKeys (i.e. two transactions are trying to write a row with the same index).
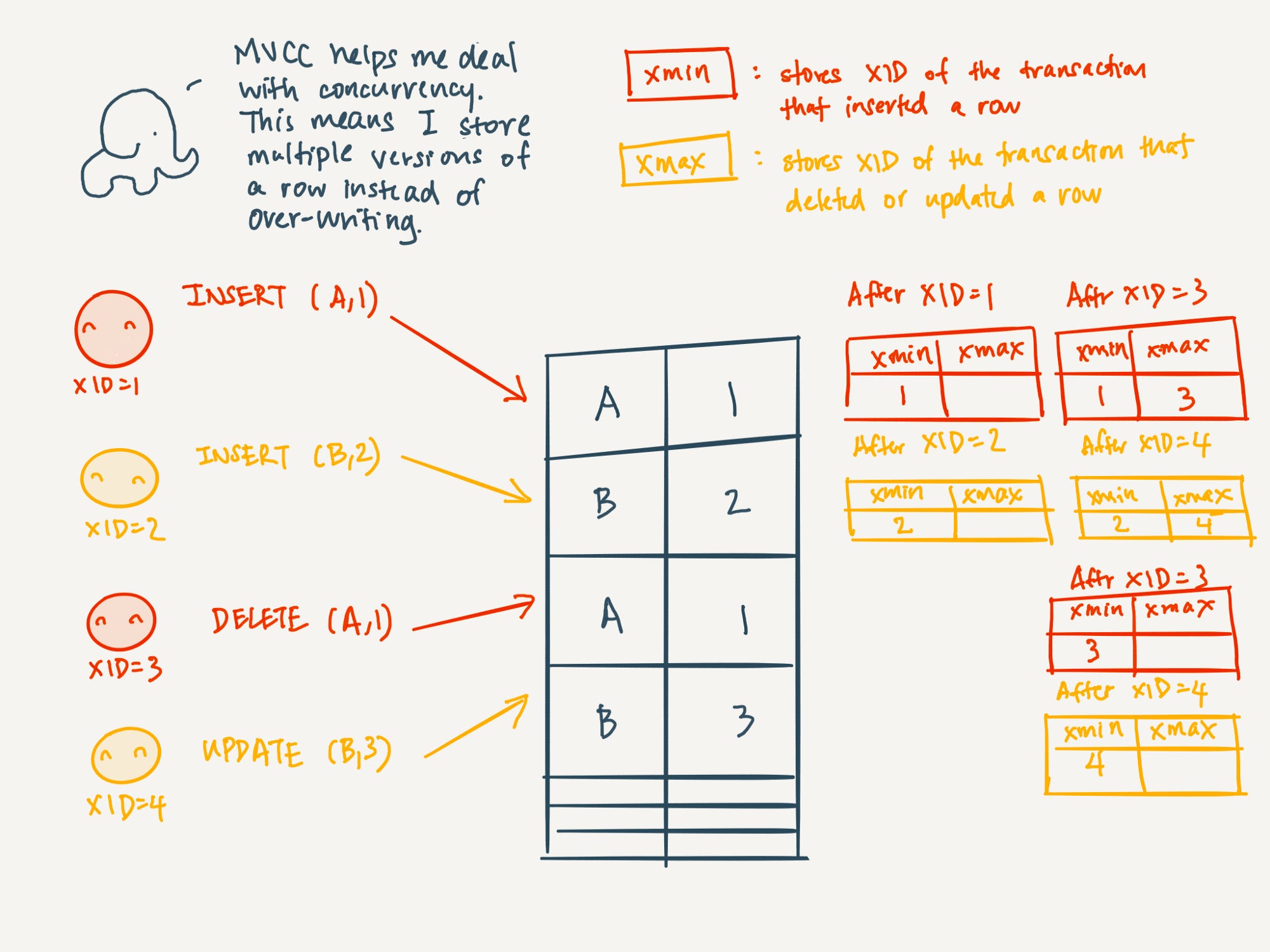
MVCC conflicts mean at a infrastructure level that transactions that could have been accepted because our network is prepared to accommodate this load, are not being successful because of the way we implemented our chaincodes’ data models. This was a real shame, because it meant that Fabric was not the bottleneck, we were being the bottleneck. Fortunately, MVCC conflicts are a well-known problem in the field of database systems, and the same schemes used for databases could be used here for the implementation of our data models. After some research we compiled the following list of potential design approaches for our chaincode data models:
No duplicate keys: MVCC conflicts appear when two transactions try to modify the same key, so we could design our data model so that every new transaction writes a completely different key, removing the problem altogether. This scheme offers the maximum throughput at a chaincode level, as no conflicts are possible.
Deltas: Unfortunately, not every data model can be implemented using “no duplicate keys”. The Delta approach is an alternative to minimize MVCC conflicts. In this scheme, every transaction looking to update a key A will write its updates in different keys. Thus, updates over a key A would be stored by transactions in independent keys such as A.1, A.2, A.3. These updates would be then aggregated and the current state of A inferred periodically, or in the next GetState where the state of A is needed (the policy to be used may depend on the specifics of the use case). A good analogy for this scheme is the way Bitcoin computes the balance of an address.
Batch processing: Using deltas complicates the design of the chaincode. If we want a simpler scheme we could implement our chaincode so it understand batches of transactions from the SDK. Instead of sending individual transactions to the peer, the SDK would batch transactions and send them to the chaincode, and is the chaincode the one responsible for aggregating the updates from the transactions in the batch. This loads a bit the level of computation required by the chaincode in every update, but it minimizes the probability of MVCC conflicts (there could still be conflicts between batches if the load is too high. This can be prevented by using Layer 2 schemes).
Intermediate caches and proxy chaincodes: The same way we use caches in the web we can use proxy contracts to cache transactions and kill MVCC conflicts early so they don’t significantly harm the performance of our network.
Layer 2 improvements: Finally, along with these designs, we could include improvements at an application and SDK level to avoid conflicts such as using a Fire-and-Forget approach for transactions, the use of a distributed transaction pools, or the implementation of queues of transactions. But let’s not get ahead of ourselves, we’ll talk about the SDK and Layer 2 enhancements in Part 4.
Apart from learning how to correctly design chaincodes data models, we also inferred other interesting best practices from our tests to bear in mind while designing chaincodes:
Be careful with how you design the functions of your chaincode. Separate as much as practically possible read operations from write operations so you can implement them as queries and invokes respectively. The life cycle of query transactions is faster than those of invoke transactions because they only need to read data from the ledger and they don’t need to be endorsed, get to the orderer, and validate signatures. Thus, try to design read operations as queries and write operations as invokes as atomically as possible to enhance your performance.
As already mentioned, depending on the Fabric version you use, reading or writing from CouchDB may be expensive, as a communication overhead is introduced, so design your chaincode in a way that you minimize the number GetStates and PutStates you do in the same transaction (some versions of Fabric already aggregate PutStates, so depending on the version you may only have to worry about GetStates).
Finally, I suggest you use random ID indexing for the keys of your data to benefit from CouchDB’s B-tree caching strategies (this paper also has a nice explanation of why you should try this).
Summarizing, take good care of your chaincodes if you don’t want them to be messing with your performance. And one last thing before I leave, as part of our analysis we even profiled the code of our peers and chaincodes. Our chaincodes were written in Go, so essentially they are a Go application that can be profiled using pprof. Amazing, right?

Learning in chaincodes
How chaincodes are designed significantly matters for your network’s performance.
Design your chaincodes data models so MVCC conflicts are avoided.
Minimize the number of requests you have to send to CouchDB.
Use random ID indexing for keys to benefit from CouchDB caching strategy.
Use invoke and query transactions in a smart way.
One last part of the series left…
We only have one last part left dedicated to the SDK, one of the most disregarded layers in a Fabric deployment (and surprisingly one of the most important and hard to make right). I really hope you are enjoying reading this series as much as I am writing it.
Part III: Protocol and Chaincodes (you are here).
Thank you for your amazing article. Please keep it up. I have one question. Can you explain more about using proxy chaincodes to to cache transactions?