
@adlrocha - What if we had Local-First Software?
The path to an offline SaaS model

For this first publication on a Thursday I want to do a “what if” exercise with you all. They say this “what if” technique was the one used by companies such as Spotify (“what if you didn’t have to own your music library?”) and Uber (“what if every car could potentially become a taxi”) to reach their current models.
So let’s try this same thing. Let’s ask ourselves: “what if the Internet was offline first? And what if we had local-first software paving the way into an offline SaaS model?” Actually, the authors of this paper (“Local-First Software: You Own Your Data, in spite of the Cloud”) raise these exact same questions in their work, and it’ll be our matter at hand today. How would an offline-first Internet look like?
The principles behind the vision
“It’s amazing how easily we can collaborate online nowadays. We use Google Docs to collaborate on documents, spreadsheets and presentations; in Figma we work together on user interface designs; we communicate with colleagues using Slack; we track tasks in Trello; and so on. We depend on these and many other online services, e.g. for taking notes, planning projects or events, remembering contacts, and a whole raft of business uses.”
We all agree that cloud apps have made our lives way easier. Efficient remote working wouldn’t have been possible without all of these real-time collaborative cloud apps we have today. In spite of this, all of these applications still pose several inconveniences and threats. To name a few: you are not the owner of the data you generate in these services, what happens if the companies behind these services go bankrupt and switch off their servers? Even more, they all rely on a centralized infrastructure, which are prone to attacks, security breaches and outages.
Imagine that you are feeling creative and you are almost done with your “opera prima” when the server fails and you realize all your work is lost. Or even worse (and a more probable scenario), what if you lose your home connection and you can’t even blame the cloud service for your lost work? Better not to mention the user experience of trying to work with these tools in a plane or somewhere without a stable Internet connection. So real-time collaboration has significantly improved our lives, but it could probably be even better.
“To sum up: the cloud gives us collaboration, but old-fashioned apps give us ownership. Can’t we have the best of both worlds? We would like both the convenient cross-device access and real-time collaboration provided by cloud apps, and also the personal ownership of your own data embodied by “old-fashioned” software.”
This is the rationale behind “local-first software,” which prioritizes the use of local storage (inside your devices) and local networks (like your home WiFi) over servers in remote data centers. Building this vision is not easy, and servers (or decentralized storages plus relays — you know where I am going with this, right? ;) —) would most definitely still be needed for backup and interconnection purposes.
So to evaluate the implications of having “local-first software”, in the paper the authors define seven ideals to strive for:
No Spinners, Your Work at Your Fingertips: I guess we can all agree that even though we have more powerful devices than years ago, software feels increasingly slow and error prone. “Local-first software” should benefit from a lower reliance on the Internet and the use of local storage to be faster than current software.
Your Work Is Not Trapped on One Device: This is a hard one. The same way current cloud apps allow you to work seamlessly from every device, “local-first software” should also enable this. Even more, it should allow you to collaborate with others (and their devices), so data shouldn’t stay exclusively in your device. A reliable synchronization system between devices will be needed to make this a reality.
The Network Is Optional, obviously: Since local-first applications store the primary copy of their data in each device’s local filesystem, the user can read and write this data anytime, even while offline. It is then synchronized with other devices sometime later, when a network connection is available. The data synchronization need not necessarily go via the Internet: local-first apps could also use Bluetooth or local WiFi to sync data to nearby devices. Moreover, for good offline support it is desirable for the software to run as a locally installed executable on your device, rather than a tab in a web browser. Although it is possible to make web apps work offline. It can be difficult for a user to know whether all the necessary code and data for an application have been downloaded. For mobile apps it is already standard that the whole app is downloaded and installed before it is used.
Seamless collaboration: Let’s illustrate this principle with a few compelling images from the paper: in short, conflicts, conflicts and more conflicts. Who hasn’t experienced this before?


The collaboration approach that I personally like the most (and the one I feel could be embedded in “local-first applications”) is the one used by git. You work in your own local version of the code, and you periodically push the changes to the repository to make them available to everyone. This is currently done manually by developers, but it could be automated in the application base code so that devices push new changes whenever a network is available. Of course, this doesn’t prevent from the appearance of conflicts, but we’ll figure out ways of solving it ,right?
The Long Now: Your data should be long-lasting. And the fact that it is stored in your local device (and potentially synchronized with other devices) can really make local-first apps perfect for this.
Security and Privacy by Default: i.e. your data in your device (and the ones you interact with), and the channel encrypted.
You Retain Ultimate Ownership and Control: This is a responsibility that in many cases users do not want to assume. And this is the reason why fallback systems such as centralized backup servers, decentralized storages, etc. should exist, so users not comfortable being responsible for their digital life can delegate their custody to others.
All this being said, how much do our current cloud applications fulfill these aspirational principles?

Not great…
The technology to make it possible
“Despite many efforts to make web browsers more offline friendly (manifests , localStorage , service workers, and Progressive Web Apps, among others ), the architecture of web apps remains fundamentally server centric. Offline support is an afterthought in most web apps, and the result is accordingly fragile. In many web browsers, if the user clears their cookies, all data in local storage is also deleted; while this is not a problem for a cache, it makes the browser’s local storage unsuitable for storing data of any long-term importance.”
Do you remember my publication on “How to make your web app work offline?”. Well, unfortunately, the “offline” designs I shared in the publication are still too “server-centric” to build a local-first application. It could make things better, but they don’t suffice to reach our goal (and fullfil the seven principles).
Then we have technologies that philosophically are already helping on the implementation of offline synchronized storage between different devices such as CouchDB/PouchDB:
“CouchDB is a database that is notable for pioneering a multi-master replication approach: several machines each have a fully-fledged copy of the database, each replica can independently make changes to the data, and any pair of replicas can synchronize with each other to exchange the latest changes. CouchDB is designed for use on servers; Cloudant provides a hosted version; PouchDB and Hoodie are sibling projects that use the same sync protocol but are designed to run on end-user devices.”
This doesn’t suffice either to fulfill all of our principles. In CouchDB you need to explicitly resolve conflicts through your application’s code (not an easy task in certain scenarios).
So is there currently any technology capable of offering the collaboration and conflict-resolution properties we need for our system? Fortunately there is, let me introduce you to Conflict-free Replicated DataTypes (a.k.a CRDTs).
CRDTs are general-purpose data structures, like hash maps and lists, but with the special feature that they are multi-user from the ground up.
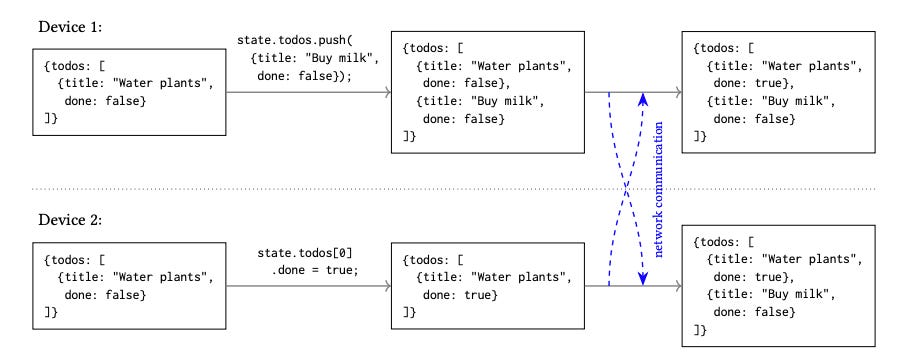
Let’s illustrate CRDTs with the image above. We have two devices with their data storage in the same initial state. Each of them perform independent updates over the data. The CRDT structure registers these changes as an update operation, so that when there is a network communication available between the two devices they can exchange their corresponding updates and merge them to reach a common state of their data structure. The only type of change that a CRDT cannot automatically resolve is when multiple users concurrently update the same property of the same object; in this case, the CRDT keeps track of the conflicting values, and leaves it to be resolved by the application or the user. So in the end the way of avoiding conflicts is designing your CRDT data structure smartly to prevent as much as possible these multi-user modifications.
“CRDTs have some similarity to version control systems like Git, except that they operate on richer data types than text files. CRDTs can sync their state via any communication channel (e.g. via a server, over a peer-to-peer connection, by Bluetooth between local devices, or even on a USB stick). The changes tracked by a CRDT can be as small as a single keystroke, enabling Google Docs-style realtime collaboration. But you could also collect a larger set of changes and send them to collaborators as a batch, more like a pull request in Git. Because the data structures are general-purpose, we can develop general-purpose tools for storage, communication, and management of CRDTs, saving us from having to re-implement those things in every single app.”
CRDTs are a field that really excites me, and there are already applications exploring their use such as Atom’s Teletype (for p2p code collaboration). I highly recommend watching this video from one of the authors of the paper to have a grasp on CRDTs. Expect a newsletter publication on CRDTs in the short term.
Some Proofs of Concept
The paper shares some PoC of “local-first application” implementations such as a collaborative Kanban board, or a collaborative drawing app.

From the implementation and the use of these apps they draw the following conclusions:
CRDT technology works
The user experience with offline work is splendid
Developer experience is viable when combined with Functional Reactive Programming
Conflicts are not as significant a problem as we feared
Visualizing document history is important
URLs are a good mechanism for sharing
Peer-to-peer systems are never fully “online” or “offline” and it can be hard to reason about how data moves in them
CRDTs accumulate a large change history, which creates performance problems.
Cloud servers still have their place for discovery, backup, and burst compute
Network communication remains an unsolved problem
CRDTs do not require a peer-to-peer networking layer; using a server for communication is fine for CRDTs. However, to fully realize the longevity goal of local-first software, we want applications to outlive any backend services managed by their vendors, so a decentralized solution is the logical end goal.
The use of P2P technologies in our prototypes yielded mixed results. On one hand, these technologies are nowhere near production-ready: NAT traversal (another interesting field of research and exploration), in particular, is unreliable depending on the particular router or network topology where the user is currently connected. But the promise suggested by P2P protocols and the Decentralized Web community is substantial. Live collaboration between computers without Internet access feels like magic in a world that has come to depend on centralized APIs.
Looking into the future
So now is when I take this “what if” exercise to the extreme and build upon my vision of a new Internet from a few weeks ago. “Local-first applications” seem like the leap forward to the Internet that we deserve in terms of UX, security and privacy. According to the authors of the paper network communication remains an unsolved problem, or does it? Within the field of web3 a lot of the solutions for the problems posed by “local-first applications” are being tackled (and many of them may be already solved).
What if I don’t want to be responsible for the storage of my data? Use a decentralized storage (Filecoin).
What if my device doesn’t have enough computation to run certain tasks? Offload to a decentralized computing service (Golem)
How can we communicate with devices behind a NAT? libp2p, NAT traversal, incentivized relays, etc. This may actually be one of the least active “works in progress” as far as I know.
How can we communicate without an Internet connection through home connections? Wifi offloading, mesh networks, etc..
So citing a recent tweet I came across: “so so so much of the decentralized web stuff out there makes NO SENSE at all, and the tiny percentage that does is so precious and wonderful.” Let’s pave the way to a new Internet with these precious and wonderful pieces of software we are building.

Hi! I'm Bohyeon Seo, a front-end developer at Korean FE Article Team.
I read an article that was introduced on https://localfirstweb.dev/ at https://news.ycombinator.com/item?id=34857435. It was a very good article and was very helpful. I am going to translate the article into Korean and post it on the Korean FE Article mailing substack https://kofearticle.substack.com/ Is that okay?
Korean FE Article is an activity that selects good FE articles every week, translates them into Korean, and shares them. It is not used for commercial purposes, and the source must be identified.
Please consider and reply. I'll be waiting!
These ones does a great job at solving a huge bulk of the problems described:
https://beakerbrowser.com
https://scuttlebutt.nz
Mentioning them here since they are not widely known.