
@adlrocha - Hash Array Mapped Tries (HAMT) to the rescue!
Building for the Web3 is hard!

Building for distributed systems and the Web3 is not easy. Let me tell you a quick story so you can get a grasp of this claim. In the scope of the Beyond Bitswap project, (which I briefly introduced in this post), we have gathered a bunch of ideas and designed a set of proposals to (potentially) improve Bitswap’s performance. This week I jumped right into the implementation of the proposal that (I thought) was the easiest to tackle. I got the idea from this paper, and it seemed pretty straightforward.
The idea is the following: In order to speed-up the discovery of content from a Bitswap node, we would inspect the requests for content of all of our neighbors and store them in a table (that we affectionately called peer-block registry) so that the next time we need to look for a specific CID, instead of blindly asking everyone around flooding the network with requests, we would ask first those peers who have shown previous interest in the file, as they potentially will have the content by now. A bit oversimplified, this is the rationale behind the solution.
In this publication, though, I am not going to talk about the design of the overall protocol, but I am going to focus in the design of this “simple” table we called the peer-block registry. We were discussing the solution in the team and I naïvely said, “come on! Building the data structure for the peer-block registry is simple, we use a Golang map structure and we are good to go”. Then, one of my wiser colleagues draw my attention about something I was disregarding, “are you aware of the number of requests for content a single node receives? Scaling that data structure won’t be easy. Do the experiment”. And so I did. These are the results of the number of WANT messages seen on a 10 IPFS nodes network with 5 seeders and 5 leechers exchanging 1000 files of 1.7MB.

Just for one of those files, a node can see up to 1700 requests for content that need to be efficiently stored in its registry in order to use this information for its future look ups. And this is for nodes with 9 connections and only half of those connections requesting content. Indeed, more challenging than I expected.
A new technique to my tool belt
The cool thing about working with people smarter than you is that they help you improve, and you always learn something new in the process. This wiser colleague of mine that encouraged me to do this test, also told me: “consider using more efficient data structures such as Hash Array Mapped Tries, they will make your problem tractable”, and (again) so I did, so this publication is my humble attempt to introduce them to you so you can also have them in your tool belt.
HAMTs are a combination of a hash table and a trie. They were introduced in this, and this paper by Phil Bagwell. HAMTs are a memory-efficient data structure where “insert, search and delete times are small and constant, independent of key set size, operations are O(1). Small worst-case times for insert, search and removal operations can be guaranteed and misses cost less than successful search”. So you can see why HAMTs are the perfect candidate for my problem at hand.
Before you jump into the description of HAMTs I highly recommend revising the concepts of Hash Tables and Tries, as if you are not comfortable with these concepts, HAMTs may be hard to understand.
A trie can be seen as “a tree with prefixes”. It is represented by a node and a number of arcs leading to subtries according to the prefix used. The following figure shows an example of a Trie with a prefix of size two that stores the values “00000000”, “11111110” and “11111111”. You see that according to the prefix and the subsequent bits, the level at which the value is stored is determined.
Source: https://idea.popcount.org/2012-07-25-introduction-to-hamt/

To transform this trie into a HAMT, we use an array to represent the tree so we have an array of length equal to the number of nodes in the tree (in this case four). Thus, there is no need to find the relevant mapping, we can use the prefix as an array index:
Source: https://idea.popcount.org/2012-07-25-introduction-to-hamt/

Unfortunately, this approach has a big memory footprint, so Bagwell in his latest paper suggested the use of an integer bitmap to represent the existence of each of the possible arcs in the trie, and an associated table containing pointers to the appropriate sub-tries or terminal nodes. Hence, the map for this first leaf:
Source: https://idea.popcount.org/2012-07-25-introduction-to-hamt/

Would be represented with the mask “1001”, indicating that only the first and the last arcs of the trie are non-null. This would result in something like this:
Source: https://idea.popcount.org/2012-07-25-introduction-to-hamt/

In short, a one bit in the bitmap represents a valid arc, while a zero is an empty arc. The pointers in the table are kept in sorted order and correspond to the order of each one bit in the bitmap. For example in our case 00 is the 0th element of the array and stores a value, and 11 is the 1st element and stores the pointer to the next layer, so the mask for the first level of the trie is 1001 as shown above (values at prefix 00 and 11). The next level has a mask of 0001, which means that there is only a value in the 11 value, and so on.
Source: https://idea.popcount.org/2012-07-25-introduction-to-hamt/

In this data structure, it becomes really efficient to identify if a key has been set. In our example at hand, by checking the mask of the root, we are able to see if there are keys starting with prefixes 10 and 01.
Operating with HAMT
The previous sections presented a simplified version of HAMTs with 2-bit prefixes and 4-bit bitmaps. The construction presented in Bagwell’s paper uses 32-bit bitmaps and 5-bit prefixes. Once understood the simple example, this is how we would perform operations on full 32-bit HAMTs.
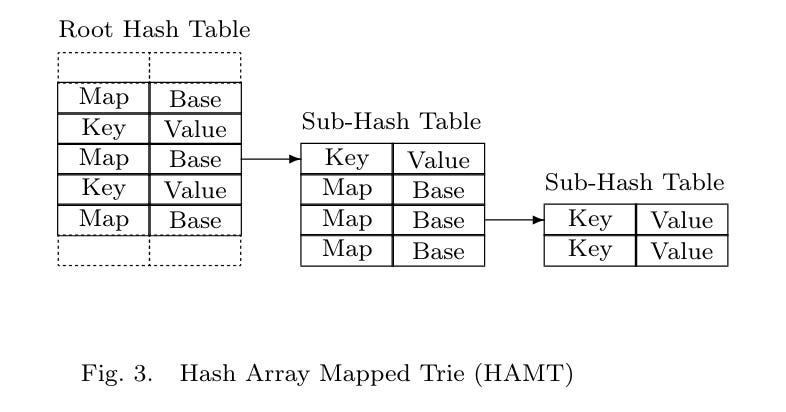
Search: Compute a full 32 bit hash for the key, take the most significant bits and use them as an integer to index into the root hash table. One of three cases may be encountered. First, the entry is empty indicating that the key is not in the hash tree. Second the entry is a Key/Value pair and the key either matches the desired key indicating success or not, indicating failure. Third, the entry has a 32 bit map sub-hash table and a sub-trie pointer that points to an ordered list of the non-empty sub-hash table entries. Take the next 5 bits of the hash and use them as an integer to index into the bitmap. If this bit is a zero the hash table entry is empty indicating failure, otherwise, it’s a one, so count the one bits below and use the result as the index into the non-empty entry list. This process is repeated by taking five more bits of the hash each time until a terminating key/value pair is found or the search fails.
Insert: The initial steps required to add a new key to the hash tree are identical to the search. The search algorithm is followed until one of two failure modes is encountered. Either an empty position is discovered in the hash table or a sub-hash table is found. In this case, if this is in the root hash table, the new key/value pair is simply substituted for the empty position. However, if in a sub-hash table then a new bit must be added to the bitmap and the sub-hash table increased by one in size. A new sub-hash table must be allocated, the existing sub-table copied to it, the new key/value entry added in sub-hash sorted order and the old hash table made free. Or the key will collide with an existing one. In which case the existing key must be replaced with a sub-hash table and the next 5 bit hash of the existing key computed. If there is still a collision then this process is repeated until no collision occurs. The existing key is then inserted in the new sub-hash table and the new key added.
Implementation time!
I hope that the above explanation has convinced you as much as it convinced me that HAMTs are a way better scheme to represent key-value data structures at the scale we have to work with in the web3 world than a naïve hash table.
At this point, I’ve chosen to do an initial implementation of my protocol with HAMTs, using CIDs as keys and the last peers that have asked for that specific CID as values. Thus, if a peer hasn’t received any request for a CID, through the HAMT bitmaps we are able to identify so quickly. Of course, this is not the whole story, HAMTs are a memory efficient key-value store, but in order for my protocol to be also computationally-efficient, additional schemes may need to be implemented such as the use of accumulators (but more about this in future publications).
To start getting some inspiration and speed-up my development, I surfed the web searching for existing implementations of HAMTs in Golang, and I could only find this simple one (which is clearly unmaintained), and this other one, still quite unmaintained but way more complete. There is also the reference implementation of the IPLD HAMT used in Filecoin, which I need to dive a bit more into the code to see if it can be used for my problem at hand.
I could also find implementations in other programming languages such as the HAMT implementation in Clojure which is also a good source of inspiration (do a quick search for HAMT and Clojure and look what I mean).
And that’s all for today, folks! The main learning I want you to take from this publication, apart from learning a bit more about HAMTs is: beware of implementing naïve approaches when dealing with the web3.0, as you may enter a performance trap (do not make the same mistake as me). At this scale we need to apply more advanced structures that scale efficiently. Throughout the development of this project I am discovering cool techniques such as these HAMTs or cryptographic accumulators that help you make web3 problems tractable. I hope to find the time and inspiration to share more about this in the next few weeks. In the meantime, have a lot of fun!
And since it has already become a tradition, follow this link if you want to become an active member of this exciting field!