
@adlrocha - Open Source is Dead. Long Live Open Execution
How AI is killing open-source and what can we do to fix it

It’s been a while since I last wrote about open-source software in this newsletter:
In 2020 I shared my opinion about how if someone wanted to seriously own their digital life they would have to go fully open-source: from hardware, to firmware, to OS, and application (something that would be a herculean task close to impossible).
In this piece from 2019 about the dark side of open-source I described how big companies were benefiting from open-source, how a lot of broadly used projects were understaffed, underfunded and undermaintained, and how open-source contributors had to work duct-taping jobs in the software industry at day to make a living only to be able to work on their spare time on what they are passionate about through open source contributions.
I even wrote in 2021 about how projects like Github Copilot (that was being released in beta at the time) was sieging open source software by benefiting from the infinite contributions from the Github community to train their models and improve their product (independently of the underlying licenses that protected the projects they leveraged). Abusing once more without fairly rewarding the open source community to help with their sustainability.
This post is an unintentional continuation to this last one in the list. These past few days the Internet has been burning by this response in a PR pushed to the popular CSS framework, Tailwind.
The PR adds an llm.txt endpoint to the project in order to make it easier for LLMs to read its technical documentation. This change was rejected by the project maintainer for clear economic reasons. Tailwind is still growing in popularity, but overall traffic to the documentation site has dropped by 40%. Their website is the primary way their users find out about their commercial products (I have to admit that I had to search for a bit myself to find their premium offering).
More and more developers use coding agents for their development work, which means that less and less humans are visiting Tailwind’s website. This has had such an impact in Tailwind’s business, that they were forced to lay off 75% of their staff (as you can read in the linked PR response).
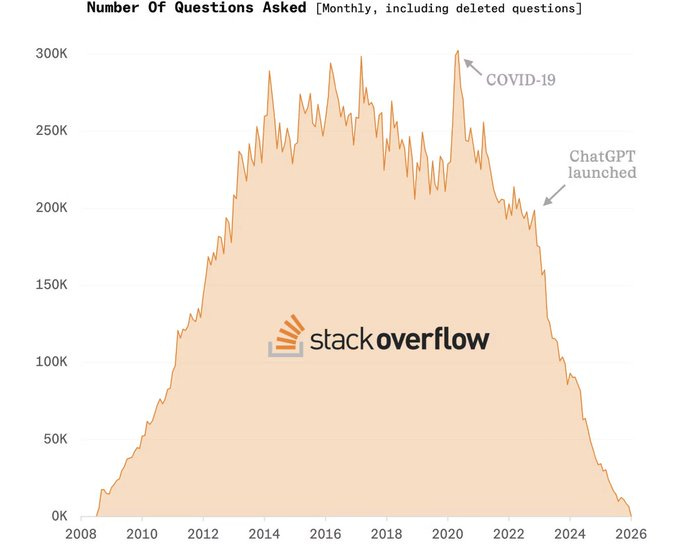
But Tailwind is not the first project that has been “disrupted by AI” lately. Other established companies in the software industry like StackOverflow have already experienced this pain themselves. The following graph shows how the number of questions asked in StackOverflow have been impacted since ChatGPT was launched. This has been clearly exacerbated since the recent popularity of coding agents
Reactions from the community have been swift: with some active open-source contributors deciding to close source all of their new contributions to prevent AIs from benefiting from it for free; to AI influencers claiming for a new economic model for content creation in the age of AI.
“The core insight: OSS monetization was always about attention. Human eyeballs on your docs, brand, expertise. That attention has literally moved into attention layers. Your docs trained the models that now make visiting you unnecessary. Human attention paid. Artificial attention doesn’t.
[...]
My prediction: a new marketplace emerges, built for agents. Want your agent to use Tailwind? Prisma? Pay per access. Libraries become APIs with meters. The old model: free code -> human attention -> monetization. The new model: pay at the gate or your agent doesn’t get in.”
> @MarcJSchmidt
All of this made me wonder, can we come up with a solution to fairly reward developers who are actively contributing to open-source, preventing them from closing their projects and stripping society from all the incredible value that they provide?
Maybe we can extend the model that we are implementing for structured data in Baselight for open source software. Let’s explore this topic in more depth.
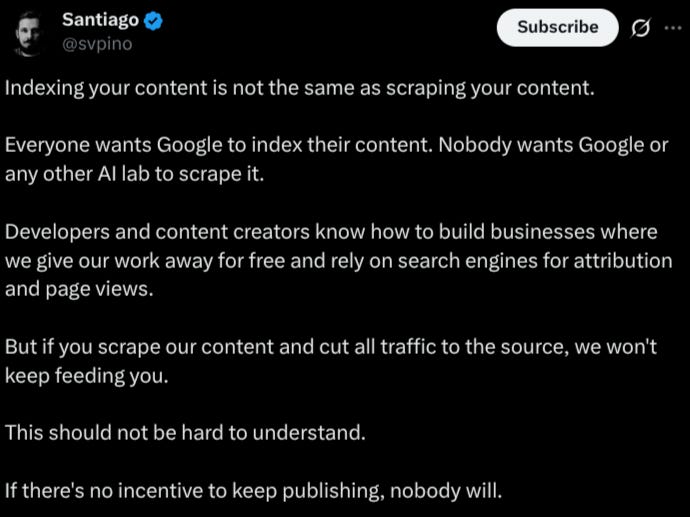
“We’re feeding AI our best work for free, and nobody is talking about what happens next.
AI will scrape every blog and social media post you publish.
AI will scrape every single open-source code you share.
AI will scrape every tutorial you record.”
@svpino
How Open Source Monetisation Works
Before jumping into potential solutions, let’s briefly explore how open-source-based companies currently make money. I would categorise these in the following classes (btw, any off-band suggestion to improve this classification is more than welcome).
The Red Hat Model
I.e. support and services. The software is free but complex. You can’t afford using it as-is for your business so you pay a company to give you a basic SLA, unlimited support, consultancy work, feature prioritisation, and timely fixes over any bugs or vulnerabilities found.
This is one of the models that may be more immediately impacted by agents. If the SLA is given for software maintenance, and I can have an agent that is capable of making patches to the software for the price of a few tokens, why would I pay a yearly fee for some work that an agent can do for me for a tenth of the price?
The Open Core Model
The core engine is free through a Community Edition (CE), but any additional and enterprise features are paid through an Enterprise Edition (EE). You can think of SSO, audit logs, role-based access control, paywalls, etc. as the kind of features included in an EE. GitLab and historically Elastic and Redis are good examples of this model.
This model is also very vulnerable to AI agents. Agents are excellent at stitching together “good enough” replacements for enterprise features. Instead of paying for the Enterprise Edition, an Agent can write custom features on top of the Community Edition in a few prompts.
Managed Hosting
The code is free, and you can run it yourself, but is such a pain that you rather pay someone else to do it. You pay a monthly subscription to have the creators host it for you in the cloud. We have dozens of examples of this: MongoDB Atlas, Vercel (Next.js), WordPress.com (Automattic), Sentry.
This is the stickiest model today because hardware isn’t free (sidenote: this builds upon my personal thesis that the marginal cost of creating software is approaching zero).
However, if an agent can optimise your self-hosted setup to be 99.99% reliable and 50% cheaper than the SaaS wrapper, the value proposition erodes. Will they be replaced then? Maybe… probably… eventually, but not yet! AI is also coming for the SaaS model, but so far agents are better at generating code than managing infrastructure, which may be glimpsing that the solution to our problem may be hidden on the execution side of the code (more on this in a moment).
The Dual Licensing Model
This one is simple. If you are building an open-source app, my library is free (GPL). If you are building a closed-source commercial product, you must buy a commercial license to use my library without polluting your codebase and forcing you to also open it. MySQL and Qt are good examples of this.
The Donations and Sponsorship Model
Finally, the one that is really keeping the long-tail of open-source alive, the donations and sponsorship model. Under this model, projects rely on donations and the sponsorship of companies (that generally leverage them) to survive. There are infinite examples of this: vue.js, core-js, Signal, curl, FFmpeg, openSSL, Debian, etc. etc. etc. This is the “attention economy” in its purest form.
Humans and organisations donate to projects and people they like, they rely on, or they think is a public good, but once this attention and use is filtered by an agent that only provides an invisible output, how can these projects gather the attention they need to collect those donations and sponsors?
As a reaction to big companies abusing the goodwill of open source software, an additional model has recently arisen, the use of source-available licenses, where you can see the code, but you cannot compete with them anymore (i.e AWS can not just run your technology and offer your service in a managed way). There have been a ton of examples of this lately, of open-source projects changing their licenses to source-available to create a moat around their project. See Terraform (Hashicorp), Redis, ElasticSearch, or MongoDB.
And while this may have slightly worked, it is a patch that has felt like a complete rug-pull for all the developers and active users of these technologies.
The Soul of the Open Source Model
Which brings us to the problem at hand. Open-source was already having an existential crisis before AI agents because the model was already not sustainable. With AI this crisis has been exacerbated. Can we do something to turn the situation around before open-source becomes extinct?
Before we explore a solution, there are a few requirements that I think should be non-negotiable:
Open source is all about communities and composability. We must ensure developers can still audit, trust, and (crucially) contribute back to projects and create derivative work. We cannot lock code in a black box that prevents community improvements (PRs, forks).
Open source contributors should be able to monetise their work and be rewarded fairly for the value they bring to the space. The model must move from ‘donation-based’ to ‘utility-based’. Core contributors of popular open-source software projects should be able to make a living out of their work.
We must technically prevent companies and agents from benefiting and abusing public contributions without consent or compensation. Licenses itself won’t do the trick, as we’ve already seen.
The solution should respect as much as possible the decentralised nature of open source.
Finally, open source has had a huge educational value for me, and it would be a shame to lose that (I’ve learnt so much by reading the code base of projects I am excited about). It may be slightly unfeasible, but we should differentiate knowledge from utility in the new model. A human reading code to learn should never be charged, a machine executing code must be metered. Knowledge is free, utility is paid.
I am probably leaving things behind, but from the top of my head these are the core values and traits of the open-source model that any alternative implementation should respect (as much as humanly and agentically possible –pun intended–).
The Glass Box Protocol: From Open Source to Open Execution

Initially, I was thinking about sharing in this post the full-fledged solution of how I am thinking about how this new model for open-source could work. However, as this is getting too long, I decided to make it a two part series, and only hype here a few strokes of the solution so we can dissect in detail in part 2.
The current model for open-source is that code == text. As long as you have access to the codebase, anyone is free to copy, train on, and replicate it. Under this model, it is hard to meter the access to the code, which is what should be gatekept to prevent indiscriminate access by agents.
This is why I am suggesting to transition the model into code == capability. You can’t copy a capability, you can only rent it.
I call this model “the glassbox protocol” and the idea is the following: instead of publishing the complete code base of a project in a code repository (as we currently do), we split open-source code into four distinct layers:
The public interface, where maintainers publish a spec and a test. This is fully open and published publicly so anyone can read the spec, see the inputs and outputs, and run the tests to verify behavior. For an initial implementation of this I am thinking about using WIT (WebAssembly Interface Type) to define the spec.
A verified blob with the implementation of that spec. The implementation code is compiled into a universal bytecode like a Wasm component. This blob blob is published along with the spec and the tests in a public registry. Why not use any executable artifact instead of limiting it to Wasm? Well, we could probably do so, but along with the executable assets I want to have a sanboxed environment where you can have a controlled (and metered execution) to support different types of paid access models. The use of Wasm also allows for fine-grain permissions and capability loading (see Wasm security model)
A manifest describing the access model and price (e.g. pay-per-execution, pay-per-download, etc.) along with other relevant metadata about the project (this is the cargo.toml or package.json of this model), like licensing, author, etc.
Optionally, some projects may want to still release the code base as we do today. That’s fine, and I think that should be supported, as both models would benefit from coexisting.
How I imagine the system to work at a high-level is that:
The maintainer publishes his project to a code repository where the spec, tests and blob is stored and indexed (this compilation can be performed locally and only upload the artifacts).
When an agent (or any user) wants to use this code it would find the capability it needs in the registry and would request its execution or imported into its codebase. This execution may require a payment defined in the manifest, and the execution is triggered according to the execution and access modes for the project (sanboxed execution, free to execute, local execution allowed, pay per cycle, etc.).
Of course, there are a lot of things that are still under-defined in this sketch: how would forks and composability work under this model (spoiler: Wasm capabilities)? How is the pay-per-access implemented (spoiler: x402)? How can the sanboxed execution be implemented efficiently? How does this model affect the different types of open source software (i.e. libraries, OS, frontend packages, APIs, etc)? Well, these last two are their own beast, so let’s leave them for Part 2.
The Path to a New Model
I was half-way into the draft of this post when I came across the tweet below which I think summarises perfectly what I am trying to achieve with this solution. We are building an index of capabilities where developers can choose how their software is accessed and distributed.
Social-based solutions like the source-available licenses have been shown to be just a patch, and not solving the problem in the age of AI. To make “code as a capability” a reality, we need to implement a technical layer for: proving execution, handling supply chain security, and managing permissions in a decentralised way.
I have some ideas involving Wasm component models and cryptographic proofs that I think finally crack the code. We’ll dive deep into the architecture, the economics, and the implementation details in Part 2. However, if you have other ideas or have been thinking about this already I would love to hear them before I write the next post (that way I can also include your inputs in it).
Until next week!